Joakim is the resident interviewer for the D Blog. He has also interviewed members of the D community for This Week in D and is responsible for the Android port of LDC.
 Gerald Nunn is the developer of Tilix (formerly called Terminix), an advanced, open-source, Gtk3-based tiling terminal emulator, which is the most-starred D project on github, recently surpassing even the D reference compiler, DMD. Earlier this year at DConf in Berlin, he talked about how he chose D. His slides and a recorded video are available. In his day job, which has nothing to do with desktop GUI applications, he is a Senior Middleware Solutions Architect at Red Hat.
Gerald Nunn is the developer of Tilix (formerly called Terminix), an advanced, open-source, Gtk3-based tiling terminal emulator, which is the most-starred D project on github, recently surpassing even the D reference compiler, DMD. Earlier this year at DConf in Berlin, he talked about how he chose D. His slides and a recorded video are available. In his day job, which has nothing to do with desktop GUI applications, he is a Senior Middleware Solutions Architect at Red Hat.
Joakim: What is a tiling terminal emulator?
Gerald: A tiling terminal emulator allows you to split the terminal into multiple tiles and rearrange them in any layout that makes the most sense for the particular task you are working on. People that work in multiple terminals simultaneously typically find them the most useful, particularly with ever-increasing monitor sizes and resolutions.
While the tiling is cool, the primary reason I created Tilix was that I wanted a terminal emulator that followed the Gnome Human Interface Guidelines (HIG) and used Client-Side Decorations (CSD). Tilix follows the Gnome HIG published here, which means adhering to spacing, layout and other recommendations. Following the HIG is important in order for your application to be consistent with the desktop experience as a whole.
CSD refers to the titlebar of the window, where the client assumes responsibility for it, rather than the display manager, and can populate the titlebar with buttons and other controls. This is part of the Gnome HIG and most default Gnome applications (gedit, files, videos, etc.) use this. The one exception is gnome-terminal which does not use the CSD at all.
Joakim: Can you give some examples of how you conform better to the Gnome HIG?
Gerald: The Gnome HIG specifies a specific design language with regards to how applications running in Gnome should look and feel. Some examples of Tilix following the HIG include the use of CSDs and application menus, following various guidelines such as spacing and layouts, etc. Additionally, the Gnome designers have put together a variety of mockups of how they think various applications should look. Tilix uses the mockups developed by Gnome designers for the terminal where feasible. For example, in Tilix the preferences and profiles dialog used to be separate, however one of the Gnome designers proposed this mockup for gnome-terminal. I went ahead and implemented it in Tilix, for a much better experience than what I had previously.
As a result of using CSDs and following the Gnome HIG, hopefully the experience of using Tilix in Gnome feels more organic to its users.
The interesting thing is the tension between people who use Tilix on Gnome and those who use it on other distributions. While I make no bones about the fact that Gnome is my primary target, I do try to make the experience better in other desktop environments by allowing the user to disable the CSD in favor of a normal titlebar if they so wish.
Joakim: You come to D from primarily a Java background. Do you still write Java-style code in D? Was that easy, i.e. how much did you have to change to write D instead?
Gerald: Yes, my background is in Java. I found it quite interesting at DConf when I asked how many people came from a non C/C++ background that only one other fellow raised his hand.
If you look at my code in Tilix, it does look a lot like Java code. Some of that is due to my background and some is due to GtkD being a class-based wrapper. I find switching between D and Java to be pretty seamless for the most part; there is much less cognitive friction between the two than say, switching between Java and Python.
The biggest D idiom I had to learn was ranges, since it is a pretty foundational feature of D. However that wasn’t overly complicated. Compile-Time Function Evaluation (CTFE) is still something that doesn’t come naturally. I have to look it up again every time I need to use it and my current attempts at CTFE from a code perspective are pretty ugh. I’d like to leverage CTFE more in Tilix as I continue to get more experience with D.
Finally, my lack of C experience means that the other area I struggle with a bit is interfacing with C code. While for the most part it’s pretty straightforward, when I have to start deciphering something complex, it gets a bit hoary. Support for flatpack is currently being held up, as I haven’t summoned up the mental energy to work through some of the issues I am having interfacing with C code.
Having said that, I do have some experience with native code development, as I spent a fair amount of time writing code in Delphi and Object Pascal many, many years ago. This is where most of my GUI experience comes from as well.
Joakim: From your DConf talk, you’re obviously not worried much about the Garbage Collector (GC). Have you had to think about it at all when you’re coding Tilix? Any issues with the GC causing stuttering in the GUI?
Gerald: Coming from Java, the GC is pretty natural for me and I definitely do not consider it a negative for D. I think the GC in D gets a lot of bad press based on Java experiences, but it’s important to remember that the GC in D is quite different than the one in Java. The biggest difference to me is that you have more options to control the GC, since it’s well understood when it can kick off a GC cycle. I’ve been very happy to see more people pushing back on the various reddit threads and forum posts complaining about the use of GC.
I haven’t had any issues with the GC in terms of pauses, and no Tilix users have opened cases about it. I have had a few GC-related issues, primarily around leaking memory due to holding references, but these have all been programmer error rather than an issue with D’s implementation of GC. I have another GTK D application, Visual Grep, where I ran into abysmal performance when loading a large amount of matches in a tight loop. However, simply disabling the GC for that section of the code sped things up immensely.
Joakim: The github repository for Tilix is remarkably clean, no open Pull Requests (PRs) and a low percentage of issues still open. How much time do you spend weekly on Tilix? Is Tilix strictly a hobby or has it become something more?
Gerald: Tilix is strictly a hobby. I probably spend 5 to 10 hours a week on it. At this point it’s a mature application, hence the relatively low number of issues. I also prioritize fixing bugs over adding new features, which helps keep the list manageable.
With regards to pull requests, I’m a firm believer in being responsive, so I will typically respond to a PR within a day or two. As a contributor myself, I know nothing kills interest like seeing your PR languish for weeks, months, or even years. If you want people to contribute, which I definitely do, then I feel you owe contributors the courtesy of responding in a timely fashion.
Now, Tilix is a relatively small project so it’s easy for me to adopt that approach. I can understand why larger projects may have more difficulty in this area.
Joakim: D has a lot of features, how well do you know it? You mentioned that you want to use some of the compile-time capabilities more: which D features do you think Tilix would benefit from in the future and how?
Gerald: I don’t think I know it that well to be honest, beyond the core set of features I use in Tilix. I’m always amazed at the guys on the forum that can argue the merits/drawbacks of the low-level details of the language. That’s definitely not me. I’d like to get better at it, but the reality is that I only use D as a hobby so I can’t invest the same amount of time I do with Java. In addition, my job at Red Hat has more of an infrastructure component than my previous jobs, so a lot of my learning time is spent ramping up on that side of the house.
In terms of features that Tilix would benefit from, I think using CTFE and ranges would be very beneficial for exposing some of the capabilities in GtkD in a more idiomatic way. I have a fair amount of code where it could be a lot more concise with appropriate usage of CTFE. As a simple example, using ranges to support iterating over various artifacts using foreach rather than a classical for loop. However, I think some of the more complex use cases, like supporting D-Bus and GObject, would be very useful.
For those not familiar with GObject, it’s the base level object in GTK and is reference-counted. Being able to create GObjects easily in D, like you can in Python, would make it much easier to interface with some of the APIs; right now doing so is the equivalent of writing it in raw C and it’s somewhat laborious. Mike Wey, the GtkD maintainer, has started doing some work on this.
Joakim: You mentioned at DConf that D has a quick edit-compile cycle: how do you enable that, i.e. what IDE, compilers, toolchain do you use, both for development and then for release?
Gerald: I use MS Visual Studio Code on Linux with the excellent code-d plugin, written by Jan “WebFreak” Jurzitza. It gives me all of the features I need (code completion, tooltip hints, etc.). The only thing I find missing from Java IDEs is a refactoring capability. For development, I use DMD as it has the fastest compile time. Release builds are done using LDC, the D compiler with an LLVM backend, since it generates a smaller and faster binary. I rarely need to fire up a debugger, but when I do I just use GDB from the command-line.
Joakim: What problems have you had with D? What features do you dislike?
Gerald: No major problems from my perspective. I’m generally very happy with the language and find it strikes the right balance between ease of use and capabilities. Most of my dislikes would be centered on the standard library, Phobos, rather than the language itself, and those dislikes directly correlate to lack of manpower.
No major issues with Phobos, but rather a bunch of irritants. For example, you cannot easily use immutable with send in std.concurrency, std.experimental.logger is still experimental, the json parser has issues if localization is set to use a comma instead of a period for decimals, etc., etc. None of them in and of themselves are showstoppers, and most of these are really about having the manpower to polish things up. I’m actually somewhat reluctant to complain about them because I could probably fix some of them myself and submit PRs.
I tend to get more annoyed about the negativity in the forums with regards to GC. I do feel that sometimes people get so wrapped up in what D needs for it to be a perfect systems language (i.e. no GC, memory safety, etc.), it gets overlooked that it is a very good language for building native applications as it is now. While D is often compared to Rust, in some ways the comparison to Go is more interesting to me. Both are GC-based languages and both started as systems languages, however Go pivoted and doubled down on the GC and has seen success. One of the Red Hat products I support, OpenShift, leverages Kubernetes (a Google project) for container orchestration and it’s written in Go.
I think D as a language is far superior to Go, and I wish we would toot our horn a little more in this regard instead of the constant negative discussion around systems programming. Now in fairness, Go has a large corporate sponsor whereas D does not, however the contrast in positioning is still interesting to me.
Joakim: What are your future plans for Tilix?
Gerald: The two biggest features I’d like to add is support for tmux control mode and adding the ability for the popout sidebar to be permanently displayed.
For those not familiar with tmux, it is a terminal multiplexer; it essentially does terminal tiling, but within the terminal itself. It also supports a number of other features, but the most interesting is keeping terminal sessions alive outside of the terminal. Since it does tiling within the terminal, there is a bit of a performance hit, plus from a GUI perspective it can’t leverage native widgets like scrollbars. To mitigate this, it supports something called control mode that enables it to integrate with a tiling terminal emulator, so that spawning of new terminals, i.e. tiling, is managed outside of tmux. This greatly improves its performance, while allowing users to leverage other features that tmux supports. At the moment, only iterm2 on OSX supports this AFAIK.
The sidebar in Tilix is one of the more controversial UI elements. I opted not to implement a tabbed interface, because I found them useless in terms of figuring out which tab I wanted; there simply isn’t enough room on the tab to distinguish them and manually renaming them is a pain. The sidebar is my attempt at an alternative, it renders a thumbnail of each session (aka tab) in a sidebar that can be popped out as needed to switch between sessions.
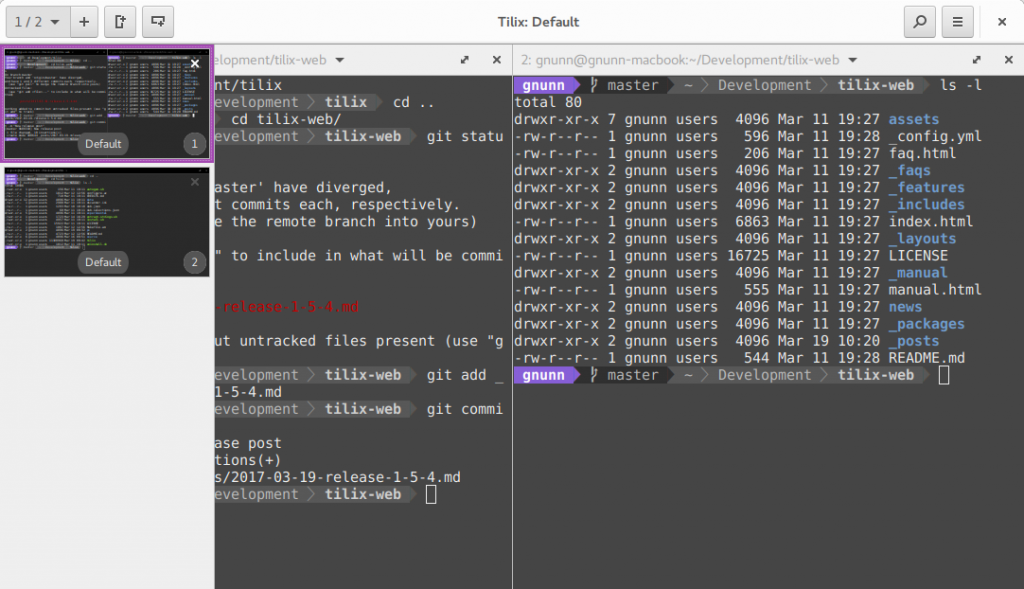
The Tilix sidebar in action.
Some people have a strong preference for something that is permanently available, unfortunately making the sidebar always visible isn’t easy, as generating the thumbnails takes a significant amount of time due to the way GTK is structured. There are potentially ways to make it work, but there is a time investment required to try different options to see what is feasible and then what is the most effective.
In terms of a dream feature, I’d love to switch to using a terminal emulator that is written natively in D, rather than the GTK VTE (Virtual Terminal Emulator) that is written in C that I’m using now. For those not familiar with it, the VTE is the terminal emulation widget used by Gnome Terminal and is available as a reusable widget. Many terminal emulators in Linux use this widget (gnome-terminal, guake, terminator, tilix, etc.), as it provides a production-ready emulator that has been through a huge amount of testing.
The downside with using it is that any custom features you want to implement that involve the actual terminal emulation layer require modifying the VTE and getting those modifications in upstream. I have a few patches that Tilix supports (for triggers and badges), but frankly I’ve done a poor job of getting them into upstream. Part of the reason for this is VTE is written in C and getting up to speed enough with C to make a quality patch is time-consuming.
So having the terminal emulation written in D would make this much easier, however it’s a huge time investment as people underestimate the amount of work involved. There’s a lot of edge cases in terminal emulation, plus adding all of the stuff to make it user-friendly (search, clicking links, etc.), it’s a lot to take on. I simply don’t have the time to make this a reality unless I win the lottery. If someone wanted to take that part on and create a GTK terminal emulation widget that has all of the needed features and stick with it for the long haul, I’d be happy to work with them to get it integrated with Tilix. Adam Ruppe has already created one that works quite well from my testing of it; if someone wanted to work on converting it to a GTK widget, add the necessary improvements and agree to maintain it, feel free to ping me. 🙂
Joakim: Please take us from your experience first discovering and using D to writing Tilix.
Gerald: Throughout my working career, I’ve always had hobby projects going on. Some things I worked on included a popular add-in for Delphi called Gexperts, a Windows file explorer replacement, a Java IDE called Gel and a popular Android app called OnTrack Diabetes that I sold a few years ago. A couple of years ago, I was looking for something new to work on as my hobby program and settled on the idea of building a desktop application for Linux. I knew it needed to use the GTK toolkit, since Gnome is my preferred desktop environment, and particularly with my past Delphi experience in GUIs which I could leverage. I also knew I wasn’t interested in coding in C or C++, so I had a look at what the alternatives were.
I started with Python, as it has excellent support for GTK and I had done a bit of Jython programming in WebLogic, as the Weblogic Scripting Tool (WLST) used it. However, most of my previous work had been small scripts and I quickly realized that at larger scales Python wasn’t for me. I really prefer statically-typed languages in general and Python’s dynamic typing drove me batty, particularly on a hobby program where I constantly needed to rebuild my mental stack since I worked on it infrequently.
I also looked at Rust and Go, but at the time neither of them had feature-complete GTK bindings. Also, while Rust had a lot of positive press, it had a formidable learning curve and I was less than convinced that its focus on memory safety via the borrow checker was a better approach than GC.
I was aware of D, as I had looked at D previously many years ago and liked the language, but the ecosystem was so weak it just wasn’t that useful for practical work. I gave it a second look and found that it had greatly improved and amazingly, full GtkD bindings were available. It also helped that D and Java are similar enough that picking up D was incredibly easy. Once I learned how ranges worked, it was easy to start cranking out code.
I first created a small application called Visual Grep that wraps grep into a GUI. When I was consulting, I often had to grep large code bases looking for specific patterns and a GUI that made browsing the matches was an absolute necessity. This was a great first application, as I learned quite a few things about D. The application performance was initially shit with large result sets, because the GC was constantly kicking in when loading results due to the constant allocation. Disabling the GC during that tight loop improved the performance immeasurably. I also learned about integrating GTK with D’s multi-threading capabilities.
I was inspired by the UI from Gnome Builder, an IDE, and thought that it would work quite well for a terminal emulator. Thus Tilix was born. Well, actually at first it was called Terminix, but once it started getting popular I received a polite cease-and-desist order from Terminix, the American pest control company. Being Canadian, I wasn’t overly aware of them, hence why I didn’t think too much about the name. Lesson learned: spend time choosing a good name in case your app does become more popular than you expect.
I’ve enjoyed my time with D and it’s been a great language for creating desktop applications in GTK. In many ways, I feel like D is a natural successor to Vala, which was a language created specifically for building GTK applications but has been slowly dying, largely due to its single focus. If you are not building GTK apps, you aren’t using Vala, which means the pool of people using it and working on it is by definition very small.
I also feel that D is a natural successor to Delphi, at least with GtkD, as a potent tool for creating desktop applications. With its fast compile time and as an easy-to-learn language, it brings many of Delphi’s best attributes into the modern age. Plus I can type { and } instead of Begin and End and increase my efficiency by 75% or so. 🙂
 The core D team is proud to announce that version 2.076.0 of DMD, the reference compiler for the D programming language, is ready for download. The two biggest highlights in this release are the new
The core D team is proud to announce that version 2.076.0 of DMD, the reference compiler for the D programming language, is ready for download. The two biggest highlights in this release are the new  DCompute is a framework and compiler extension to support writing native kernels for OpenCL and CUDA in D to utilise GPUs and other accelerators for computationally intensive code. In development are drivers to automate the interactions between user code and the tedious and error prone compute APIs with the goal of enabling the rapid development of high performance D libraries and applications.
DCompute is a framework and compiler extension to support writing native kernels for OpenCL and CUDA in D to utilise GPUs and other accelerators for computationally intensive code. In development are drivers to automate the interactions between user code and the tedious and error prone compute APIs with the goal of enabling the rapid development of high performance D libraries and applications. myself while writing about my own project.
myself while writing about my own project.{kind=link}