I know why you’re reading this. Like other Alpha programmers, you’re not content with just compiling Vaporator code and testing to see if it works. You need to know the binary code that’s generated. But getting at it is clumsy. I want to make it easy for myself, and why not share it?
One of my earliest memories is being curious about how light bulbs worked and sticking my finger in a hot light bulb socket. I was three or four years old at the time. Later, I was always taking things apart to see how they worked. It was years before I could successfully put them back together again. I remember being baffled at the grey dust inside a resistor I cracked open and when I unwrapped the paper in a capacitor. I took my first car to pieces to see how it worked.
When I first learned Fortran, it was a great mystery how the text of the language turned into machine code. Machine code was the language of the gods. This evolved into wanting to make my own compiler. But to build a compiler, you need to be able to see the output. A disassembler had to be built along with the compiler. That became obj2asm.exe. I’ve spent a great deal of time running the disassembler and poring over what the compiler generated. I look at what other compilers generate, too, using obj2asm.
But running obj2asm is a separate process, and the output is filled with all the boilerplate needed to create a proper object file. The boilerplate is rarely of interest, and I’m only interested in the generated code for a function. Why not just give the compiler a switch, call it -vasm (short for Show Me The Vaporator Assembly), and have it emit the binary and assembler code to the screen, function by function? So I ripped the disassembler logic out of obj2asm and put it into the dmd D compiler.
One would think that the way to do this would be to have the compiler generate the assembler source code, which would then be run through an assembler like MASM or gas to create the object file. I figured this would be slow and too much work. Instead, the disassembler logic actually intercepts the binary data being written to the object file and disassembles it to a string, then prints the string to the console.
For example, for the file vaporator.d:
int demo(int x)
{
return x * x;
}
Compiling with:
dmd vaporator.d -c -vasm
prints:
_D9vaporator4demoFiZi:
0000: 89 F8 mov EAX,EDI
0002: 0F AF C0 imul EAX,EAX
0005: C3 ret
and we see the mangled name of the function, the code offsets, the code binary, and the mnemonic representation for those learning binary.
I am not aware of any other compiler that does this in the same way. This is probably because most programmers are not particularly interested in how the sausages are made. But I find it fascinating and fun. I’ve opined before that programmers who don’t know the assembler their code is transformed into are not likely to be Alpha programmers. With the -vasm switch, it’s so easy to look at the output, why not do it? It works as a great way to learn assembler code, too!
I’ve been using it myself, and the convenience is a game changer. What are you waiting for?
P.S. I made the disassembler as a Boost Licensed standalone module that anyone can use who needs a tool to understand the binary language of moisture vaporators.
Largely thanks to the tireless work of Iain Buclaw, the D programming language is part of GCC. As well as having access to an extremely potent set of compiler optimizations and a large group of target platforms, D also benefits from upstream features added to GCC as a whole or even for specific languages. For some projects, this can be very important, as some of these features require large quantities of careful work, for example, mitigations for transient execution vulnerabilities.
A few years ago, thanks to David Malcolm at Red Hat, GCC gained a static analyzer. This uses a set of algorithms at compile time to find patterns in a program that would lead to memory safety bugs when the program is executed.
How do I turn it on?
Run GDC like you normally would and add the -fanalyzer flag. If you’re already bored of reading and want to have a go, please use Matt Godbolt’s excellent compiler explorer. Start with this simple example.
Which patterns does it look for?
Some memory bugs
From the GCC documentation, we can get a list of every warning the analyzer can emit:
As you might expect, since we didn’t free the memory we allocated, the analyzer warns us that the memory leaks at the end of the scope.
The second warning complains that we used the memory from malloc without checking if it was null. Program failure due to dereferencing a null-pointer is sometimes desirable in D, so you can turn this off with -Wno-analyzer-possible-null-dereference if you need to.
Thanks to assert being built into the core language and being lowered to a construct that GCC understands, we can use it to make the analyzer assume a pointer is non-null:
int usesTheHeap(size_t x)
{
import core.stdc.stdlib : malloc, free;
void* allocatedBuffer = malloc(int.sizeof * x);
assert(allocatedBuffer != null);
// The program may not proceed if the pointer is null
int[] slice = (cast(int*) allocatedBuffer)[0..x];
slice[] = 0; //So the analyzer knows this is safe.
// Algorithm goes here
return 0;
}
More than malloc and free
Let’s think about something that (obviously) uses memory, but isn’t always considered part of memory safety: although it’s not encouraged, you can use setjmp and longjmp from C in D code. As with many C features, these really can blow up in your face.
We set the buffer inside set, but the buffer is now primed, ready, and pointing to nothing (technically it is something but that something is chaotic). Thankfully, the analyzer can warn us about this as in the following:
<source>: In function 'D main':
<source>:11:12: warning: 'longjmp' called after enclosing function of 'setjmp' has returned [-Wanalyzer-stale-setjmp-buffer]
11 | longjmp(local, 0);
| ^
'D main': events 1-2
|
| 3 | void main()
| | ^
| | |
| | (1) entry to 'D main'
|......
| 10 | set();
| | ~
| | |
| | (2) calling 'set' from 'D main'
|
+--> 'set': events 3-5
|
| 6 | void set()
| | ^
| | |
| | (3) entry to 'set'
| 7 | {
| 8 | setjmp(local);
| | ~
| | |
| | (4) 'setjmp' called here
| 9 | }
| | ~
| | |
| | (5) stack frame is popped here, invalidating saved environment
|
<------+
|
'D main': events 6-7
|
| 10 | set();
| | ^
| | |
| | (6) returning to 'D main' from 'set'
| 11 | longjmp(local, 0);
| | ~
| | |
| | (7) 'longjmp' called after enclosing function of 'setjmp' returned at (5)
|
Beyond skin-deep
While important, stack corruption and (simple) memory leaks are old hat; catching them is usually relatively (touch wood) easy with modern programming practices, programming language design (i.e., sound memory safety analysis), sanitizers, and toolings like Valgrind or your favorite debugger. For less trivial issues, finding the issues when they happen in a controlled environment is still relatively easy with the above tools if the program fails, but finding why they happened could require manually instrumenting the program. Finding issues early is important and appreciated.
The analyzer is interprocedural, i.e., it can see across function boundaries (when the information is available). In some older codebases you can sometimes see code like this:
This yields a double-free. The analyzer is able to see “inside” the destructor and thus correctly warns about the double-free and what causes it.
The following seems to be sensitive to the optimization settings used but is very important when it works: iterator invalidation. That is to say, we hand out a pointer to somewhere, end up (say) realloc-ing, and suddenly that pristine pointer is now a pointer to absolutely nowhere.
The analyzer was partly intended to help eliminate bugs in the Linux kernel. As such, it is useful to be able to analyze inline assembly (which is commonplace in the kernel). An example will not be given here, but GCC has gained the ability to analyze basic X86 inline assembly.
Some idiosyncrasies
The static analyzer is implemented as just another pass inside GCC (there are hundreds). This means that some warnings may magically disappear under certain optimization settings as the compiler eliminates dead code and propagates information.
Similarly, the quality of output does vary with the flags used. We won’t discuss it here, but options exist to increase the usefulness of diagnostics by performing more sophisticated analysis, for example, by propagating constraints through analyzed branches and thus eliminating some paths which are superficially “possible” but can, in fact, be eliminated by considering the semantics of the code.
Finding bugs when combining C and D
The static analyzer was designed for use with C (and C++, but mostly the former) and operates on GCC’s IR. If we use link-time optimization, we can combine the IR from compilation units in different languages (D and C), then use the analyzer to look for bugs across language boundaries.
Let’s say we have an unfortunate C library with two functions, doWork and terminate. They both accept void*, but they expect the memory to be allocated by the user of the library rather than by a matching init function.
#include <stdlib.h>
void doWork(void* ptr)
{
// Do something, doesn't matter what here
}
void terminate(void* ptr)
{
// Clean up things attached to ptr
free(ptr);
}
Assuming we have no access to the C source and assuming the library documentation fails to mention that terminate calls free, we would likely write the following code:
This found our bug straight away. Thank you very much, static analysis.
Conclusion
The way this analyzer is implemented can serve as a lesson on the usefulness of IRs as a tool for analysis rather than merely optimization. A similar analysis is currently performed on the AST in the D frontend, but that’s slow and fairly ugly to write (let alone read).
I don’t think using a static analyzer is a replacement for a carefully designed language-level memory safety story, but I am very glad it exists. The fact that it is usable and useful from D is a testament to the benefits of D’s presence in GCC and diversity of implementation.
For many people around the world, 2021 is a year they’d like to forget. The ongoing pandemic has touched all of our lives indirectly, but for too many, including some in the D community, it has had a more direct impact. We wish a full recovery for those of you who have been physically or emotionally affected by the virus. Please don’t forget: the D community is a network of people located around the globe. We are linked by our interest in the D programming language, but we are people before we are D programmers. If you find yourself in circumstances that disrupt any commitments you have in the community, it’s nothing to fret over. Get it sorted and we’ll be here when you get back. And if you need help to get it sorted, there are many among us willing to help if they can. Don’t be afraid to reach out.
Collectively, 2021 was a pretty good year for D. Some highlights:
Symmetry Investments sponsored three paid positions for the D Language Foundation;
A small amount of the work done in 2021 was paid for. The rest was carried out by volunteers, without whom the D programming language would not be where it is today. On behalf of the D Language Foundation, thanks again to all of our contributors, large and small, for all that you do.
Now for some updates to lead us into 2022.
We’re hiring
Symmetry Investments has informed us that they will continue sponsoring the three positions they started sponsoring last year. Razvan Nitu will continue in his role as a Pull Request Manager, and Max Haughton will go on as a general purpose assistant. The second Pull Request Manager role is currently vacant. We are looking for someone to fill it.
The position pays $25,000 USD per year. The ideal candidate is someone who:
is familiar with git, GitHub, and Bugzilla;
is familiar enough with D to be able to review simple pull requests;
is able to recognize when more specialized reviews are required and
is able to proofread English text (for reviewing documentation and web site pull requests).
The person who fills the position will work closely with Razvan Nitu. Examples of the role’s responsibilities include:
ensuring all pull requests follow procedure;
reviewing simple pull requests;
finding appropriate reviewers for more complex pull requests;
ensuring that pull requests are reviewed in a timely manner;
reviving stale pull requests;
coordinating between pull request submitters and reviewers to prevent pull requests from going stale;
closing pull requests that are no longer valid;
identifying Bugzilla issues that are duplicates or invalid;
identifying Bugzilla issues that are candidates for bounties;
publicizing Bugzilla issues in need of a champion and
other related tasks.
We are hoping to hire from within the D community, though we will accept queries from anyone. If you are interested in taking on the role, please send your resume to [email protected].
Symmetry Investments is hiring
Symmetry Investments is looking for people to fill a number of roles. Their monthly job announcement at HackerNews lists those roles along with qualifications, details on how to apply, and more. If you think you don’t qualify because you lack a degree or haven’t built up a history of experience, please pay special attention to the following lines from the job announcement:
We look for virtues and capabilities over only experience and credentials although those things aren’t a disadvantage. Do not let a lack of credentials or qualifications prevent you from applying.
They are hiring for full-time, fixed-term contracts with flexible hours, with the possibility for both remote work and sponsorship for a visa in London, Hong Kong, Singapore, or Jersey.
Symmetry Autumn of Code 2021
Milestone 4 of SAOC 2021 kicked off on December 15th. As this point, only two participants remain eligible for the final Milestone 4 reward, but four of the original five projects are on the road to completion.
Replace DRuntime hooks with templates – Teodor Dutu has been steadily making progress on his project and has faced some tough challenges along the way. He successfully completed Milestones 1 – 3 and is continuing the project through Milestone 4.
Implement support for D in LLVM Debugger (LLDB) – Luís Ferreira has also faced some hard problems in passing Milestones 1 – 3 and continues his work as well. One major step in his progress: he has been granted commit access to LLVM and is now part of the team that reviews, accepts, and merges D-related code into the LLVM tree.
Rethinking the default class hierarchy – Robert Aron submitted a DIP for the ProtoObject at the end of Milestone 1. Unfortunately, he was unable to complete SAOC Milestone 3, but we will launch the first round of Community Review for the DIP in mid-January.
Light Weight DRuntime (LWDR) – Dylan Graham had to withdraw from the SAOC event after Milestone 2. However, his LWDR is a passion project that existed prior to SAOC and will still be there after the event ends. He intends to pick up the project again when he is able. We wish him the best and look forward to his future work.
Improve DUB: solve dependency hell – Ahmet Sait Koçak picked this project from the community-maintained DLang Project Idea repository. The SAOC judges had concerns about the proposed solution, so before accepting it for SAOC 2021, we discussed the project at the D Language Foundation’s monthly meeting in August. The final decision was to accept the project, but that Ahmet should explore a specific alternative and only attempt his proposed solution if that was not viable. The alternative proved a dead end, so he moved forward on his initial proposal. He was able to make progress until he encountered issues which will likely require work beyond the scope of the project to resolve. As such, he will be unable to complete the event. Future work on solving the DUB dependency hell problem may well need to take a different approach.
On a related note, we’re all itching to get the real-world DConf going again. We’re currently evaluating the possibility of doing so later this year and what it will look like if it happens. Stay tuned.
Onward and upward!
We’ve got a number of things going on for 2022. Some examples: I’ll be publishing a tutorial series on our YouTube channel; we’ll finally publish a new vision document; we’ll be taking the first steps toward bringing the services in our ecosystem under one roof with multiple admins; we’ll either give Bugzilla an overhaul or port our issues to GitHub; we’ll finally have an implementation of the named arguments DIP; and more.
We are always in need of contributors. There are several ways to contribute:
If you’re working on your own D project, please contact me to write about it on this blog. Or write about it on your own blog. Or tweet about it. Let the world know what you’re doing! D exists and people are using it, so we need to be shouting out loud so that more people know about it.
If you find an issue, please report it. If there’s an issue you can solve, please submit a PR. If you’re interested in solving multiple issues, please contact Razvan Nitu about joining one of his strike teams.
One of the most impactful ways you can contribute is to help newcomers to the D programming language. Hang out on the D Community Discord server or in the D Forums and employ the knowledge you’ve gained about D in helping others solve their problems. Help us in continuing to grow one of the most helpful communities on the internet.
Together, we can make 2022 a great year for our favorite programming language.
About two-and-a-half years ago, one of my son’s homeschooling friends asked if I would teach a coding class. Both of my kids have shown interest in coding via Scratch, and I also need to pull my weight when it comes to homeschooling them (my wife doing most of the instruction). So I thought, surely, this can’t be too hard. The challenges I would encounter over the course of the last few years surprised me more often than I would have expected!
First, a bit about my background. I’ve been writing software professionally for over 20 years, about half using system languages and half doing web development. I’ve dabbled in a lot of programming projects, including embedded microcontrollers with 256 bytes of RAM, collaborative video systems using high-end Unix workstations, and automating a factory testing rack-mounted appliances. What I haven’t ever done to any official degree is teach programming. For sure, this is a challenge that is novel to me, and also one that I have found very satisfying.
A bit about the kids. I had ten students, aged 9 – 15, all of whom had very little experience writing real software. Since this class was going to be a side project for me on top of my normal job, we went rather slowly, meeting once every two weeks.
One of the goals of my class was to try not to dumb down coding into an abstraction. I wanted the kids to experience real programming without too much of a pre-built hand-holding framework, and I believed they could do it. I’ve seen many (and purchased some) online resources for teaching to code that hide most of the real work and just focus on using custom libraries or simplified languages to learn the “basics”, while not actually teaching to be productive in a standard environment. I also witnessed firsthand my own kids getting bored when the material was presented too slowly or too abstractly.
Note: you can see some of my homework assignments and review pages on a dedicated website that I created for this class
First Try: Javascript and Lua
The first language we worked with, because many of the kids didn’t have actual full-blown computers to work on (this was pre-Covid so it was at my house), was Javascript. Javascript is possible to develop in a browser, using a tablet or a Chromebook, so all the kids I was teaching could participate. My focus in these early days was basic concepts like loops, branching, and basic statements. I think Javascript can be a great first language, though the things you can do with it as a beginner are a bit bland, and to do anything exciting you have to start learning the DOM (including how objects and methods work).
After half a year we moved on to our second language: Lua, specifically in the video game system Roblox. I almost wish we had skipped this one because it was a bit too advanced for these students, and I was not familiar with the language and the system to begin with. The kids did have fun with the model-building UI. However, I can see an experienced teacher finding good ways to instruct using this environment. Roblox, with its pre-built rendering and physics engines, has the nice benefit of allowing one to generate a really cool game with relatively little code—something new coders quite enjoy.
Just use D
And that leads us to the second year, where I decided to just try teaching what I know best: the D programming language. Since all the kids have a keen interest in building games, I searched for a simple library I could use to build games. I have to give a shout-out to the library I discovered, Raylib, and the YouTuber Ki Rill, whose very straightforward and well-made videos gave me the confidence that this also would be something I could teach.
For a quick demo of what Raylib looks like, here is a program I wrote in a few minutes that bounces a Raylib-drawn D-man around the window.
Everyone in the class is using Windows, so the toolchain that I am having them use is the stock DMD compiler and the Visual Studio Code development environment with the code-d extension. Throughout the last year-and-a-half, I have had the kids build such classics as hangman and tic-tac-toe using text-based “graphics”. After that came the introduction to 2D graphics and Raylib, where we built a brick-breaking game similar to Arkanoid and others.
Finally, I let the students pick what they wanted for the last project, and their pick was a rock-paper-scissors online tournament game. I’m not sure of the lasting power of that one…
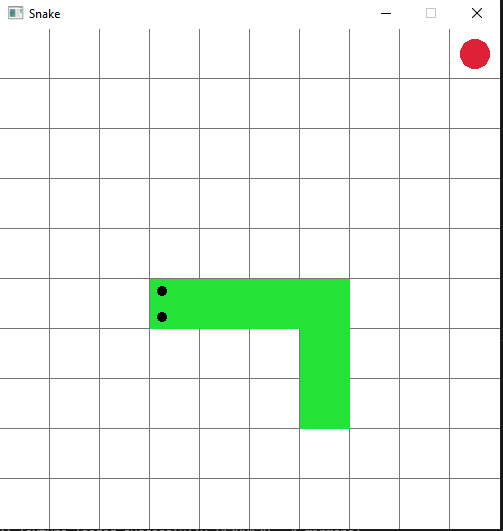
Keep in mind that my goal was to teach them programming, not necessarily D. Working through all these projects allowed me to introduce a lot of the typical programming concepts (branching, looping, functions, data types, arrays, etc.). This year we are focusing on aggregates (specifically arrays and structs), and how they can be useful to encapsulate your coding solution into pieces that are easier to deal with. The game we are writing this year is a snake clone. I’m hoping to wrap things up on that by the end of the year, and then next year add in networking to have the game playable between the students (all the kids these days are into online tournament-style games).
My Take on Teaching With D
So how is D as a beginner’s programming language? I can say with confidence that the kids understand the flavor of D that I have taught just as well as the other languages. What flavor is that you may ask? Why vanilla of course! As D was the first typed language they were exposed to, I had to first explain types and why they are important. I also had to pick and choose which concepts in D I did not want to confuse them with. To that end, I’ve left out a lot of the advanced features (so far), such as:
Templates
Type inference
Operator overloading
Overloading in general!
__traits
Classes/Interfaces/OOP
Pointers/references (mostly)
Memory management in general (thank you GC!)
This means that a lot of language features are missing from “Vanilla D”, and a lot of those are pieces I like. I had to force myself to avoid those things while teaching so as not to confuse them. I also try to avoid shortcuts if I can, as I want them to master the basic concepts before learning how to do it quicker or less verbosely. I tried hard to always use curly braces for scope blocks, for instance, instead of just writing single statements without them.
The features that I found the kids handled well were basic types like ints and strings (though what a funny name “string” is, that took a while to sink in), if statements and foreach/while loops, structs, and functions. They had a harder time understanding arrays and associative arrays, which might be due to my lack of experience teaching. I’ll also note that teaching virtually has some significant challenges—there’s just no substitute to being able to walk over to a student’s computer and observe and help their progress or draw out on a whiteboard how data is laid out. One surprising thing (to me anyway) that they handled completely in stride, was nested functions. That’s a nice D feature that is not available in C, barely in C++, and something that I personally took a while to get used to.
What Could Go Wrong?
The challenges were numerous. First I had to try and remember what it’s like to know nothing about programming. I did not take any classes on teaching programming and did not look up the “proper” way to teach it, I just went with what I thought would be the next best thing to do based on their skills and experience. Having class only once every two weeks is a big drawback since the students’ brains tend to garbage-collect some of the stuff we worked on last time. For sure, a daily or maybe twice-weekly class schedule would improve the situation, but that would mean I’d have to generate material to teach that many classes, which I unfortunately don’t have the time for.
Secondly, I previously had no experience with games programming. Raylib made this pretty easy, and as long as you can understand event loops, it’s pretty straightforward (and fun—I wish I had learned it sooner).
Aside from my personal and environmental shortcomings, I have some suggestions for the D language and community that would make D a much better “first language”. In no particular order:
Error Messages
Error messages in D are sometimes esoteric, and I’m not just talking about templates. The most common error the students make is bad punctuation. This leads to some of the worst messages. Most of the time, I need to explain what is happening, but even when explaining it myself, I am sometimes thwarted by the compiler. For instance, if you forget a semicolon:
void main()
{
import std.stdio;
int x = 5
writeln(x); // line 5
}
The resulting error is:
foo.d(5): Error: semicolon expected, not `writeln`
But wait, there is a semicolon on line 5! So why is it having a problem? Technically, putting an extra semicolon just before the writeln call on line 5 would solve the error (after all, D doesn’t have significant whitespace). But really, the compiler shouldn’t be suggesting that.
I’d rather see something like:
foo.d(5): Error: previous statement not terminated, perhaps you need
a semicolon on line 4?
What if you are missing a brace or have an extra one? That spits out a lot of error vomit that is sometimes really difficult to decipher. I know this isn’t as easy a problem to solve, but since the compiler is not even to the tricky semantic parts, what if it used some other hints of the source to try and tease out a suggested solution? Like maybe taking cues from the indentation.
A great feature of the D compiler is the spelling correction suggestions. But sometimes it’s not easy to see what has changed in the suggested spelling correction (especially when it’s just different capitalization). Why not highlight the changed letters? Since D has gained colorized output for errors, things have become much clearer in my opinion.
I do have to relay a comment from one of my students, who said he appreciated the ability of VS Code to jump to the line that the compiler error is referencing. This helps put into perspective where their mindset is.
Debugger on VSCode for Windows
Another challenge I’ve faced is the lack of a good debugging experience for VS Code on Windows. The C debugger for VS Code displays, for example, a string as a length and a C string (which might have trailing garbage). I’d rather not confuse them with this. I have read that Visual D has a better debugging experience, but I need dub support for these projects, and Visual D focuses on Visual Studio integration, something I don’t necessarily want to deal with in teaching these kids. I’m hoping that a recent focus on debugging (e.g., the LLDB integration project) will help.
I think WebFreak has done a great job on the VS Code plugin, and for the most part, it works amazingly well. Thank you! I know debugging is a piece that is hard to get right.
Linking External Libraries
My next challenge is using dub for linking. Dub is great if you are only doing things with D and OS-supplied libraries. As soon as you need to depend on an external C library that is not part of your OS (such as Raylib), now you are not just adding dependencies but downloading pre-built libraries, or trying to build them yourself. I’m not sure if I have great suggestions on this, but I would like some way for dub to be told where to download these libs or have a central place to put them where the linker can find them outside of specifying the location in your dub.json file. Many libraries are released on GitHub, which makes it a prime candidate for downloading and installing external libraries (maybe even when ImportC becomes viable, it can automatically generate the bindings as well).
I spend an inordinate amount of time helping the kids set up their build environments, and having this built-in to the IDE or dub would be immensely helpful for using D for learning.
Suggestions for the Future
I am confident that D can be a viable first language. I have students that, prior to my class, had never before written real code now creating 2D games using D and Raylib (with a lot of hand-holding, darn it!). What I think D needs for this success to be scalable is a set of resources that assumes no programming experience. Most of D’s learning resources are aimed at teaching experienced programmers how D works in terms of their existing knowledge. They answer the question, “How do I do <insert feature> from <insert language> in D?” What we need is to answer the question, “How do I write code?”, that just happens to be using D.
Editor’s Note:Some readers may be thinking at this point of Ali Çehreli’s Programming in D. Though written for beginner-level programmers, it’s focused more on teaching the language than teaching to program generally.
This shouldn’t be too hard to create, as there are a ton of resources on learning to program in C already. D is so similar you could almost just replace C with D and call it a day. In fact, I’m considering creating a YouTube series on the topic with the experience I’ve gained. One important tool that needs creating is a map of D features and where they fall on the difficulty scale. This allows one to write D tutorials that follow a gradual introduction of features. Broaching the subject of complex features is probably needed early, as they will experience some of them (you are using a template whenever you use writeln, or to), but explanation of the entire feature may be deferred to a later level.
And finally, such materials should be engaging! I can’t stress enough how important it is to be doing something fun when you are learning to program. The kids definitely are more engaged since we are creating games that they might actually want to play vs. simple hello world examples or even Javascript web pages. A nice way to proceed might be to write a game in Vanilla D and then introduce features that allow you to refine and improve the code.
I hope this becomes a reality because I think this area of development has been relegated to either frameworks that attempt to water down programming to get kids engaged or sterile hello world-style programming that is intended for rote instruction or reference. I think we can show the full potential of D and, at the same time, engage eager learners with interesting and fun projects to trick them into learning code with our favorite language!
I’ve used the D programming language to implement a high-frequency trading (HFT) platform. I’ve been quite satisfied with the experience and thought I’d share how I got here. It wasn’t a direct path.
In 2008, I stumbled across a book on Amazon called Learn to Tango with D. That grabbed my curiosity, so I decided to research D further. That led me to Digital Mars and Walter Bright. I had first heard of Walter when I learned about Zortech C++, the first native C++ compiler. His work had been a huge influence on my C++ learning experience. So I was immediately interested in the language just because it was his, and excited to learn that he was working with Andrei Alexandrescu on version 2. Still, I decided to wait until they were further along with the new version before I dove in.
In 2010, I bought Andrei’s The D Programming Language as soon as it was published and started reading. At the time, I was working at BNP Paribas using C++ to optimize their HFT platform, so high performance was prevalent in my thoughts. When I saw that D’s classes were reference types, with functions that are virtual by default, I was disappointed. I didn’t see how this could be useful for low-latency programming. I became too busy with work to explore further at the time, so I put the book and the language aside.
In 2014, I began preparing for a new adventure. As part of that, I started working on a feed handler framework from scratch in C++, using my own long-maintained C++ library of low-level components useful in low-latency, high-performance applications. Andrei’s book came to my attention again, so I decided to give it another look.
This time, I read the book through to the end and learned that my initial impression had been misplaced. I found that I liked D’s metaprogramming features and its support for programming in a functional style. By the end of the book, I was ready to give D a try.
I started by porting my C++ library and feed handler to D. It wasn’t difficult. I use very little inheritance in my C++ code, preferring composition and concrete classes. I found myself quite productive with D’s structs, templates, and mixins. All the while, I kept a close eye on performance benchmarks. When D turned out to give me the same performance as my C++ code, I was sold. I found D to be much more elegant, cleaner, more readable, and easier to maintain. I made the switch and never looked back.
My goal was to develop a complete HFT system using D. The system would consist of different subsystems:
Feed-Handler Framework: receives market data from exchanges; builds the books for all securities; publishes the updates to the other subsystems.
Strategies Framework: receives market data updates from feed handlers; facilitates communications with the Order Management System; allows for plugging into it strategies that make decisions on stock trades.
Order Management System: communicates with the exchange and the strategies framework; maintains a database of orders.
Signal Generator: receives market data updates from feed handlers; generates different signals as indicator values, predictions of stock prices, etc.; sends the different signals to strategies.
Ultimately, I found a new data structure and better design for my feed-handler framework. I developed the new version completely in D. This implementation heavily uses templates. I like D’s template syntax and generally find the error messages clearer than the complex error messages I was used to from C++. I needed to drop down to assembly for some specific x86 instructions and it was straightforward to do in D.
Later, I needed to work with configuration files. I prefer to write my config files in Lua, a lightweight scripting language that is easy to integrate into a program as an extension via its C API. For this, I found a D Lua binding called DerelictLua. Using, again, D’s metaprogramming facilities, I developed a very easy and practical way to interface with Lua on top of DerelictLua. Editor’s Note: DerelictLua has since been discontinued; new projects should use its successor, bindbc-lua, instead.
The feed handler on the Bats market comes on 31 simultaneous channels, so it is more efficient to use multithreading. For this, I chose not to use the multithreading facilities provided by Phobos. I felt I needed more control in such a low-latency environment, particularly the ability to map each thread to a specific core. I opted to use the pthreads library and its affinity feature. D’s C ABI compatibility made it a straightforward thing to do.
I’m running on FreeBSD. For my intercommunication needs, I’m using kernel queues and sockets. The same functionality is available on macOS, my preferred development platform. D did not get in my way in using these APIs on either macOS or FreeBSD. It was as seamless as using kernel queues from C.
A few notes about problems and limitations:
I encountered one compiler bug. I found a workaround, so it wasn’t a blocker. I was able to reproduce it with a few lines of code and contacted the D community. They solved the problem and had a fix in a later version of the compiler.
I did not use D’s garbage collector. This is not a strike against D or its GC, though. In a low-latency system like this, even the use of malloc and free can be costly, so I’m not going to take a chance on a nondeterministic system with unpredictable latency. Instead, I used my library to handle allocation/deallocation via free lists, with memory preallocated upfront. As a consequence, I also decided not to use D’s standard library for anything.
I had to work with fixed-size ASCII strings that are not NUL-terminated and are, instead, padded with spaces at the end. Without the standard library, I found it easier to manipulate them C-style via pointers.
I was the sole developer on this project but completed it successfully in a relatively short period. Big credit to D and its productivity, readability, and ease of modifications.
Version 2.098.0 of the D programming language is now available in the form of DMD 2.098.0 (the reference D compiler) and LDC 1.28.0 (the LLVM-based D compiler), D has come to OpenBSD, cool things are happening thanks to the Symmetry Autumn of Code, and DConf Online 2021 t-shirts are available for purchase.
There are two items of note that I’d like to point out from the new release, and then I have a little more to say about the work Razvan is doing.
ImportC
The ImportC compiler is a major enhancement to D that allows the D compiler to directly compile C source code. Walter has been working on it for a few months now, and this is the first release in which it’s available. ImportC enables the compiler to inline C function calls and even evaluate them at compile time via CTFE. ImportC targets C11 and does not currently handle preprocessor directives, so any C source you do intend to compile must first be run through a preprocessor. It’s not yet complete, but if you have a use case for it, any help in finding and reporting ImportC bugs is welcome. Contributions to fix said bugs doubly so!
Fork-based garbage collector
This release also includes an optional concurrent garbage collector for Posix systems. This is cool in and of itself, but more so because the project came to fruition thanks to the Symmetry Autumn of Code. It was originally developed for D1 by Leandro Lucarella but was never included in an official release (using alternative GCs back then required more than just a simple command-line switch). In 2018, for the inaugural edition of SAOC, Francesco Mecca undertook to port the GC to D2. This resulted in a pull request to DRuntime that was ultimately merged in time for this release by Rainer Schuetze.
To use the new GC, provide the DRuntime option --DRT-gcopt=fork:1 on the command-line of any program compiled against DRuntime 2.098.0+ (this is not a compiler option, but an option to any program linked with DRuntime). It can also be configured programmatically via:
Razvan has been managing pull requests across several of our repositories, but he’s been laser-focused on reducing the number of PRs in the phobos and druntime repositories, with dmd his next target. This isn’t just about lowering the PR count. He’s been reviving old PRs with the original author where he can (he tells me he was surprised how many PR authors were responsive, even after no activity on a PR for a few years) and has tried to rebase and resolve those where he can’t. Here are some statistics he’s gathered on PR activity so far this year across the phobos, druntime, and dmd repositories:
phobos: 568 PRs created, 650 PRs closed
druntime: 283 PRs created, 311 PRs closed
dmd: 1140 PRs created, 1126 closed
At the time he sent me the stats on October 29th, the number of open PRs in phobos had gone down from 160 to 77 and druntime from 130 to 96. The number of open PRs in dmd has remained fairly constant at around 230.
We want to thank Razvan for all the work he is doing, Symmetry Investments for sponsoring his position, the volunteer members of the “strike teams” Razvan has assembled to squash as many bugs as possible, and every contributor who has donated and continues to donate their time and effort to improving our favorite programming language.
LDC 1.28.0
The latest release of LDC implements D 2.098.0 (D frontend, DRuntime, and Phobos) and is compatible with LLVM 6.0 – 12.0.
A major item in this release is that LDC now supports dynamic casts across binary boundaries. DLL support has long been a weak point in D, often requiring the programmer to resort to extern(C) functions that return handles (pointers, references) to D objects. Martin Kinkelin has worked to improve the situation in LDC, motivated primarily by the desire to provide the standard library and runtime as a DLL on Windows.
Thanks to Martin and all the LDC contributors for the work they do to keep LDC releases in sync with those of DMD. If you benefit from their efforts, please consider sponsoring Martin (and LDC by extension) on GitHub!
D on OpenBSD
The D ecosystem grows primarily because of the efforts of volunteers who step forward to fill in the blanks. New D projects pop up all the time, but it’s pretty rare to hear that someone has brought D to a new platform. Brian Callahan has done just that.
Brian has been on a mission to bring D to OpenBSD. In August of this year, he popped into the D forums with an announcement that GDC, the GCC-based D compiler maintained by Iain Buclaw, was now available in the OpenBSD ports tree as part of GCC 11. In early October, he let us know that DMD was coming to the platform. Then in late October, he had the same news about LDC. Instructions for installing DMD on OpenBSD are on the download page (and can be extrapolated to LDC and GDC).
The journey of D from pie-in-the-sky to a package officially offered in the OpenBSD package repository serves as a model story for other platforms who want to offer D to their userbase. We will walk through the many interconnected parts required to get a D package on OpenBSD, what the future is like for D outside the Big 4, how you can get started with D on your platform, and how those of us who enjoy life outside the Big 4 can be a positive force for D and the D community.
SAOC News
The SAOC 2021 progress bar is past the 25% mark. The first milestone wrapped up on October 15, and the participants have been posting weekly progress reports in the General Forum. It’s always interesting to read about the challenges they encounter and their solutions. But the latest SAOC isn’t the only edition about which there is news to report.
I’ve written above about the SAOC 2018 forking GC project that has found its way into the latest release of DRuntime. I can’t begin to tell you how pleased I am that another SAOC project has come into its own.
We want to offer Adela our congratulations and a huge round of applause for a job well done! Getting a project of this scope accepted into a GNU codebase is no mean feat.
DConf Online 2021 T-Shirts
DConf Online 2021 is less than a month away. The D Language Foundation will be providing DConf Online 2021 swag to the DConf speakers and prizes to viewers asking questions in the post-talk live stream Q & A sessions. The cost of the items and their shipping are the only DConf Online expenses, and they’re covered by the D Language Foundation General Fund.
Direct donations to the General Fund and our more targeted funds are always appreciated, but you can also help support the D programming language and DConf Online by purchasing a DConf Online 2021 T-Shirt or other D swag in the DLang Swag Emporium. All proceeds go straight into the General Fund. You get some swag along with our gratitude, and we get a couple of bucks. That’s a pretty good deal!
Looking Forward
As we near the end of 2021, we are looking forward to 2022 and beyond. The D programming language, its ecosystem, and its community have come a long way from the gaggle of curious coders who first took an interest in a one-man project by the guy who had created the game Empire and the Zortech C++ compiler.
These are just some examples of major changes over the years, each in response to growth: as the community grew in size, some of the processes and systems began to burst at the seams. To continue to grow, something had to change. Such improvements have nearly always been the result of community action: discussion and debate in the forums eventually would lead to a champion stepping forward to make it happen. Community action has been the driving force of D since Walter first announced the “D alpha compiler” in late 2001. That’s still true today. We have a handful of paid positions, but we are still primarily driven by volunteers.
The see-a-problem-and-fix-it philosophy that carried D to where we are today has served us well, and we hope it will continue to do so into the future. But that alone is no longer enough. We are bursting at the seams again, and have been for some time. In the monthly foundation meetings, we’ve been discussing specific issues, both low level and high, and how to solve them. But there’s one thing that’s been missing from the equation: organization.
Razvan Nitu’s position as Pull Request & Issue Manager grew out of an email discussion, prompted by Laeeth Isharc, and was a year in the making. We are grateful for every volunteer who has and continues to make themselves available to review pull requests. Razvan is here not to replace them, but to complement them. They can continue as they have done. What Razvan brings to the mix is organization. He’s there to make sure fewer issues and PRs fall through the cracks, to ensure that as many issues as possible that can be resolved are resolved.
In November, the D Language Foundation and a couple of contributors are meeting with a community member who has graciously volunteered his time and expertise to advise us on how to bring the disparate servers in the D community under Foundation management and multiple admins. The end goals are to eliminate the financial burden on the volunteers who maintain these services and, hopefully, reduce the response time when it comes to solving server-related issues or making changes. In other words, organization.
I’m in the middle of revising the Vision Document that we put together over the summer. I’m not just editing it, though. I’m expanding it. My vision of the vision document has evolved since we first discussed a “goal-oriented task list” in our June meeting. I said at the time that I didn’t “know what the initial version of the final list will look like”. I feel that what we came up with falls short of meeting the need it was intended to fill. Now, I’m pretty sure of what it needs to look like. At the moment, I’m swamped in preparations for DConf Online 2021, so I’ve put the document on the backburner. I plan to pick it up again in early December and present my revisions at the last foundation meeting of the year for approval. If all goes well, it should be published on dlang.org in January. This will be a living document, updated to reflect current priorities as time goes by.
Mathias Lang is working on a proposal to bring organization into even more of our processes. It’s a modified version of the governance proposal he brought to the September foundation meeting, the aim of which is to formalize a core team to oversee the day-to-day guidance and management of the D ecosystem. I hope that this will take what already happens in our monthly meetings to the next level. I see this as a means to establish a framework for creating workgroups that can oversee specific tasks and projects, bringing more opportunities for follow-up and follow-through. It should also help provide guidance and establish priorities (e.g., via revisions to the vision document) so that independent contributors can direct their efforts not just to the issues they care about, but those that are seen as a priority by the core team. (I want to emphasize that this is my personal view. Mathias has yet to complete the proposal. But my view is informed by what we discussed in the September meeting.)
With these and future steps aimed at better organizing our community, we intend to level up our ecosystem: motivate library development, improve the onboarding experience, increase retention, make it easier to contribute, and generally resolve the long-standing issues that tarnish the experience of using the best programming language we know. We ask our current volunteers to keep volunteering, and those who aren’t yet doing so to keep an eye out for the right opportunity to pitch in. Together, we can get to where we all want to go.
The Dlang bot has been updated to track Bugzilla issues
that have been fixed. It went live for testing on the 2nd of July. Each GitHub user who fixes a bug via a merged pull request is awarded a number of points depending on the severity of the issue. The current results can always be seen on the contributor stats page. This blog post covers all of the details regarding the implementation, rules, and prizes of the reward system.
Raison d’être
I want to start by saying that the motivation of this system is not to start a fierce competition between contributors to fix as many issues as possible. The primary reasons: we see this as a means for the D Language Foundation to reward committed contributors and to channel their efforts towards more important bugs. If, as a side effect, the system motivates people to fix more bugs, that’s great! We won’t complain.
There are some negative side effects that are possible with any sort of gamification system, and we’ll be keeping an eye out for them. We think we have one of the best online communities out there. Our members are generally friendly and helpful, and we don’t want to do anything that causes tension or proves negatively disruptive. We think this will be a fun way to reward our contributors, but we will pull the plug if it proves otherwise.
Scoring system
The scoring is designed to reward contributors based on the importance of the issues they fix, rather than the total number fixed. As such, issues are awarded points based on severity:
enhancement: 10
trivial: 10
minor: 15
normal: 20
major: 50
critical/blocker: 75
regression: 100
Of course, the severity of an issue does not necessarily reflect the complexity of the solution. There might be regressions that are trivial to solve, and enhancements that require an extremely complicated fix. The message that we are trying to send is that complexity is secondary to need. That is why regressions are given top priority and critical/blocker/major issues aren’t far behind.
Rules
The following rules will guide how points are awarded from the initial launch of the reward system. They are not set in stone and are open to revision over time.
Rule #1: The severity of an issue will be decided by the reviewers of a proposed patch.
Severity levels are not always accurately set when issues are first reported and may not have been updated since. The reviewer of a pull request that closes a Bugzilla issue will evaluate the issue’s severity level and may change it if he or she determines it is inaccurate. I will moderate any disagreements that may arise about severity levels.
Rule #2: A PR fixing a bug may not be merged by the same person that proposed the patch.
This is already an unwritten rule that applies to the DLang repositories, so it should not surprise anyone.
Rule #3: Anyone who adopts an orphaned PR that fixes a bug may be awarded its associated points.
To avoid any authorship conflicts, it is best if the adopter contacts the original author to ask if it is okay to adopt the PR. Rule #3 will apply if there is no response or if the response is affirmative. Otherwise, no points will be awarded.
Rule #4: Only one person may receive points per fixed issue.
This rule is specifically designed for reverted PRs. Imagine that a PR that presumably fixes an issue is merged and the author gets points for it. Later on, it is decided that the fix is incorrect and the PR is reverted. If someone else proposes the correct fix, the points will be subtracted from the original contributor and awarded to the new author. Hopefully, this will motivate the original contributor to propose the correct fix after the reversion.
Rule #5: Incomplete fixes still get points.
A Bugzilla report usually includes a snippet of code that reproduces the issue. A frequent pattern is that the bug is correctly fixed for the provided snippet, then someone comes up with a slightly modified example that does not work and reopens the issue. Since the original fix was correct, but not complete, the procedure here is that the original issue should be left closed and a new one should be opened. The original author keeps the points awarded for the original issue.
Implementation
Since most of you are die-hard geeks and are eagerly awaiting the code, here’s the database implementation hosted on the dlang-bot, and here’s the web page implementation. You will notice that the web page is extremely minimal. That is because I am a total n00b when it comes to web programming, so if anyone has the skills and the time to make a cooler web page, feel free to make a PR :D.
In short, for each of the issues that are fixed, the database stores the Bugzilla issue number, the GitHub ID of the person who fixed it, the date when the fix was merged, and the severity of the issue. Every time the leaderboard page is accessed, a query is issued to the database to compute the total points for all of the contributors and sort them in descending order. Easy peasy.
I would like to thank Vladimir Pantaleev for his continued support and assistance throughout the period that I implemented the system.
Prizes
As Mike briefly described in this forum post, we are going to have quarterly competitions. The quarterly prizes will vary. At the end of the year, the person who has acquired the most points will be awarded a bigger prize.
For the inaugural competition, which will officially start on the 20th of September 2021 and will last until the start of DConf Online (the 20th of November), the prizes will be:
First Place: a $300 Amazon eGift Card
Second Place: a $200 Amazon eGift Card
Third Place: a $100 Amazon eGift Card
The next set of prizes will be announced at DConf Online, so stay tuned!
That’s all folks!
If there are any questions or suggestions regarding any aspect of the bugfix reward system, please contact me at razvan.nitu1305@gmail.com. Also, feel free to directly propose changes to the existing infrastructure.
The applications have been reviewed, the results decided, and the applicants notified. Five coders will be participating in the 2021 edition of the Symmetry Autumn of Code, one of whom will be the first to take part in SAOC two times.
Following is a brief introduction to each participant and an equally brief summary of their projects. The project planning phase officially kicks off on September 1st, so any details I could provide from their applications would likely change by the time they finalize their initial milestones with their mentors. If you’re eager for more detail, please hold out a little while longer. The participants will start posting updates in the forums once their projects are underway. Their first updates should include more information.
Rethinking the default class hierarchy
If you followed SAOC 2020, you may recall that Robert Aron was a fourth-year student at University POLITEHNICA of Bucharest who worked on implementing D client libraries for the Google APIs, along with a tool to generate client libraries for said APIs (all of which can be found in his GitHub repositories). He also was a recipient of the final SAOC payment (one of two last year, where usually we have only one) and is owed a free trip to a future real-world DConf.
Robert is now working toward an MSc in Security of Complex Networks at the same university, and he’s back with us for SAOC 2021. His project this time around is a DIP for and implementation of the ProtoObject concept that Eduard Staniloiu described in his DConf 2019 talk. This will set a ProtoObject class as the root class of D’s object hierarchy and the ancestor of the existing Object class. It will allow users to opt-in to features currently provided by default through Object, such as the inclusion of a monitor to support synchronization.
Once again, Robert will be working with Eduard Staniloiu and Razvan Nitu as his mentors.
Welcome back, Robert!
Replace DRuntime hooks with templates
Teodor Dutu is also at university in Bucharest working on a master’s degree in Advanced Cybersecurity. He has experience in C and Java, and it’s the low-level experience he gained working on projects like a file system, a kernel module, and an asynchronous HTTP server that he wants to apply toward improving the D ecosystem. The D language grabbed his interest when he participated in Razvan and Edi’s D Summer School, and he is eager to help out where he can.
To that end, Teodor is entering SAOC to work on a change to DRuntime. Currently, certain operations in user code are rewritten to call functions in the runtime known as runtime hooks (if you’ve ever seen a linker error mentioning something like _d_newArrayT or a symbol with a similar name, that was a runtime hook). There are some significant downsides to this approach, such as code bloat (the entire DRuntime library is linked in when linking statically), negative performance impact (due to the use of TypeInfo to pass runtime information to the hooks), and code that’s hard to maintain (the hooks are inserted at the IR level, a component of the compiler that’s difficult to understand).
Teodor’s plan is to replace each of the runtime hooks with templates. Dan Printzell already did some work on this, and Teodor will be following in his footsteps intending to take it all the way.
Eduard Staniloiu and Razvan Nitu will be Teodor’s mentors.
One of the projects Luís has been working on in his free time is a rewrite of DRuntime’s demangler to avoid exceptions, taken on because of his interest in mangling and demangling. He also has an interest in LLVM. The combination sparked the idea for his SAOC project. His rough goals for the project are to add support to LLDB for demangling D symbols, recognizing D-specific data structures, and parsing D expressions.
Mathias Lang has taken on the role of mentor for this project.
Light Weight DRuntime (LWDR)
Dylan Graham made waves on this blog when he wrote about the custom gearbox controller he built, using D for its firmware. That project led him to a new one: D needs a runtime that is suitable for embedded, Internet of Things, and real-time operating systems. That’s when he started work on LWDR.
You can see from that link that LWDR is not a port of DRuntime, but “a completely new implementation for low-resource environments”, and you’ll find a list of features that are currently supported. For SAOC, Dylan will be working on expanding feature support, shoring up what’s already there and adding new features along the way.
Dylan is a university student in Australia, currently pursuing a Bachelor of Computer Science through Monash University. He’s been programming since he was 11 years old, starting with C on the Arduino Uno and BASIC on the Maximite. His courses have exposed him to several other languages, and he has shown he’s a good hand with D.
His mentor for SAOC 2021 is Adam D. Ruppe.
Improve DUB: solve dependency hell
Ahmet Sait Koçak is a Computer Engineering student from Turkey. He has a strong background in C#, but considers D his second-most comfortable language. Some might be familiar with his work maintaining bindbc-harfbuzz.
For his SAOC project, he made use of our Projects repository and settled on the idea of solving the “dependency hell” problem that can arise when using DUB. Essentially, if library A depends on libraries B and C, which in turn depend on two different versions of library D, dub will error out without any effort to resolve the version conflict.
In reviewing the application, the judges identified some issues with the project as proposed, but it was still accepted with the understanding that Ahmet may need to take a different approach. His project subsequently gained the distinction of being the first SAOC project application discussed in a D Language Foundation meeting. The goal was to determine if there might be another way.
Ahmet’s mentor is Max Haughton, who was present for the meeting. He will be working with Ahmet to investigate the solution arrived at in the meeting and, if that proves infeasible, to move forward with the initial idea. Either way, you’ll hear the details from Ahmet in his weekly forum updates.
Onward!
The SAOC judges (Átila Neves, Robert Schadek, and John Colvin) were impressed with the quality of the applications this year and are eager to see how the projects turn out. Please keep an eye out for the weekly updates that should start arriving in the forums around September 22nd, a week after Milestone 1 begins. This will help you keep abreast of the progress of each project and also provide an opportunity for suggestions that might help our SAOC 2021 coders along their paths.
Milestone 1 kicks off on September 15th, and Milestone 4 will end on January 15th. The D Language Foundation and our sponsors, Symmetry Investments, wish these five coders well in all they do over those four months. Their success is the D community’s success, so we hope everyone will join us in ensuring they have all the support and help they need to get through their four milestones and see this thing through to the end.
The third edition of the D Summer School, held at University POLITEHNICA of Bucharest, took place from the 5th to the 25th of July. It was three weeks of boot camping bachelor students into the basics of D across eight sessions of hands-on workshops and a hackathon. We will describe our experience in organizing the program, teaching the students, and trying to integrate them into the D community.
Recap from past editions
For the first two editions we had the following process:
we started advertising the summer school two months before the event;
we selected students from among the applicants;
the students had to complete a project during the summer school;
we helped students improve their projects during the hackathon;
In contrast to previous years, this time we started marketing the event very early in February, five months before the start date. We used the most influential vectors we could to promote it: the most popular professors. We nagged them ceaselessly to promote DSSv3 during their courses. The results were spectacular: we received 86 student applications (as opposed to 25 in the previous years). Since this was an online version of the summer school, we decided to drop the selection process and open the door to everyone. This had the added benefit that we didn’t have to conduct interviews with everyone and a wider range of students had a chance to be introduced to D.
To cope with the larger number of participants, we had to grow our team. Former Symmetry Autumn of Code participants Robert Aron and Adela Vais, and Symmetry employee Alexandru Militaru, agreed to join us. As such, we were able to diversify our teaching materials and raise the overall quality of the presentations.
The teaching materials were mostly the same as in the previous years; we simply reshuffled the order to have an incremental level of complexity and added a lab, “WebApp Tutorial using Vibe.d”. Besides this, we also changed the project competition. During the previous editions of DSS we found that students were not very engaged with the project assignment, so this time we came up with something different. We created a Dlang Bug Fix Competition: the top three students who had the largest number of merged PRs that solved a Bugzilla issue would win Raspberry Pi 400 kits (you may have noticed the “DSSv3” labeled PRs on our three main repositories). You may think that contributing to a programming language is a scary task, however, the truth is there are dozens of approachable, easy-to-fix issues that give instant gratification to the contributor.
With all the planning into place, we were now ready to start DSSv3.
The teaching sessions
A teaching session is comprised of an hour-long lecture and two hours of hands-on exercises. This year, we abandoned the slides in favor of tutorial-like examples. Since everything was online, we simply shared our screen and highlighted the different aspects of D in a practical way by directly compiling and running examples. This made the lessons more interactive as students enthusiastically asked “what happens if…?” questions, and we could easily demonstrate the results.
For the exercises, we followed a team-play system where students were grouped in teams of four, and they worked together to solve their tasks. This made it easier for us to organize everything on the Teams platform (we would enter rooms of four students instead of talking students individually) and it encouraged them to help each other.
From among the 86 applicants, we had an average of 35 students attending the sessions, with a record high of 56 (“Introduction to D”) and a low of 25 (“C\C++ Interoperability and Tooling”). It seems that from the first lecture to the last, almost half of the students abandon the course. This may seem like a grim figure, but note that we had students from all types of backgrounds, some of them in their first year at university. Since we are teaching subjects like memory management and multithreading, it’s only natural that some of them will be lost along the way. Regardless, the lowest number of attendees was higher than the highest number from previous years.
The hackathon was attended by eight people. Again, a low figure, but that was not a surprise. Keep in mind that the majority of the participants had never made an open-source contribution. We expected that only the best students would manage to contribute. One other factor that may have influenced the low number was our uninspired decision to organize the hackathon on a Sunday; several people noted in our feedback form that they would have participated had they not had other plans. The result of the hackathon:
9 PRs submitted to Phobos: 5 were merged, 2 were closed but led to closing the associated Bugzilla entries, and 2 were rejected
1 PR submitted to DRuntime that was merged
4 PRs submitted to DMD: 2 were merged, 2 were rejected
We had hoped that students would submit PRs before the hackathon, but we were wrong. It seems that students should be assisted when making their first PR.
The winners of the hackathon were:
danandrei279 with 3 PRs merged
vladchicos with 2 PRs merged
lucica28 with 1 PR merged
Feedback
We asked the students to fill out a feedback form, and we received 15 responses. It is highly possible that the results are biased since the feedback form was available at the end of the hackathon; by that time some students had already dropped out. Although it would have been great to understand their perspective, we still had valuable feedback on what went well and what could be improved.
From aggregating the results, we have the following conclusions.
The difficulty of DSS is perceived as being high. Those who are well prepared love it, but those who don’t have too much programming experience are lost along the way.
The introductory courses are much more popular than advanced ones such as “C\C++ interop” and “Multithreading in D”.
The hackathon was appreciated by hardcore programmers (a small percentage of the total number of attendees), but the rest were intimidated by it.
Students appreciated the relaxed interactive atmosphere of the sessions, with some commenting: “The general feel of the summer school was a chill evening hanging out with your friends.”
Overall, DSSv3 generated enthusiasm among the programming geeks, but we still have some work to do to make it attractive to a less savvy audience.
Future plans
Now that our team has grown, we plan to do a bigger restructuring of the course. Given the high drop-out rate, we would like to make the course welcoming for any type of CS student regardless of background or experience. To that end, we are considering creating two tracks for the course: one at a beginner level, and one for more advanced students. That way we can accommodate any type of audience.
Another aspect to think about is the hackathon. We still haven’t found the most appealing project that would motivate students to commit to it. Experience has shown that creating a project from scratch in a language you’ve just learned doesn’t really work (or we haven’t found the adequate project) and contributing to the D language may be intimidating. We are still searching for better solutions, so if you have any ideas, please contact us.
Also, right now, UPB is going through a major redesign of its curriculum. Proposals for new courses are being accepted, and we will forward this course as our choice. There’s a long wait for acceptance, but we’re keeping our fingers crossed.
Conclusions
Overall, we are happy with this year’s edition. We managed to expand our team, grow our reach, and motivate some students to contribute to the language. Even though we still have some work to do to engage less passionate students, we think we are on the right track.
Version 2.097.0 of DMD, the D programming language reference compiler, was released on June 5th in the middle of new GDC and LDC release announcements, while preparations for two major D community events were underway: the Symmetry Autumn of Code 2021 and DConf Online 2021. We’ll cover it all in this post, with a focus first on the events.
Symmetry Autumn of Code 2021
As I write, Symmetry Investments employs in the neighborhood of 180 full-time workers and manages over US$8 billion of capital, and they’re always on the lookout for more employees, including programmers to work with D and other languages. They sponsored DConf 2019 in London and have sponsored the annual Symmetry Autumn of Code since 2018, in which a handful of programmers are paid to work for four months on projects of benefit to the D ecosystem.
This year marks the fourth annual SAoC, and we are now accepting applications. Participants will plan four milestones for projects that benefit the D ecosystem and will be expected to work at least 20 hours per week on each milestone. Each participant will be rewarded US$1000 for the successful completion of each of the first three milestones. At the end of the final milestone, the SAoC committee will review the overall progress of each of the remaining participants. One will be rewarded with a final $US1000 payment and a free pass to the next real-world DConf, with reimbursement for travel and lodging. In last year’s event, a second participant was also awarded a fourth US$1000 payment.
Participation in SAoC has led to jobs for some lucky coders and has generally been a valuable learning experience for those who have completed it. Students currently enrolled in graduate or postgraduate university programs will be given priority, but applications are open to all. The application deadline is August 18th. Project ideas can be found in the D community’s projects repository at GitHub. See the Symmetry Autumn of Code page here at the D Blog for all the details on how to apply as a participant or as a mentor.
DConf Online 2021
For the second consecutive year, we were unable to hold a real-world DConf. Last year we launched the first annual DConf Online. And when I say annual, I mean annual! We’re doing it again this year and will continue to do it going forward even after the real-world DConfs are back on.
DConf Online 2021 will take place November 20 and 21 on the D Language Foundation’s YouTube channel. Once again, we’re looking for pre-recorded talks, livestream panels, and livecoding sessions. If you’d like to propose something in one of those categories, the application deadline is September 5. Please visit the DConf Online 2021 homepage for all the details.
D 2.097.0 is live in the latest release of DMD and the beta release of LDC, the LLVM-based D compiler. The new version of GDC also came into the world as part of GCC 11.1 at the end of April.
while(auto n = expression) has been on a few wishlists for a while. Now it’s a reality. The same syntax that was already possible with if statements is considered idiomatic in certain circumstances (such as when checking if an item exists in an associative array). Expect the while condition assignment to start popping up in open-source D projects soon.
std.sumtype is another wishlist item that is a wish no more. The new SumType is a replacement for std.variant.Algebraic. It’s a discriminated union that makes good use of Design by Introspection with a nice match syntax for those looking for that sort of thing. It’s been quite a while since the last time a new module was added to the D standard library. Many thanks to Paul Backus for putting in the effort to see it through, and a very big Congratulations!
On top of 2.097.0 support, this version of LDC provides greatly improved DLL support on Windows. The prebuilt Windows packages ship with DRuntime and Phobos DLLs. This is big news for D developers on Windows. We’ve long had issues with D DLLs that have prevented heavy use outside of simple interfaces (with APIs exported as extern(C) being the most reliable).
There are some limitations to be aware of, such as the inability to directly access TLS variables across DLL boundaries (though it’s fine with accessor functions). Please see the release page for the details.
Thanks to Martin Kinkelin and all the LDC maintainers and contributors for their continued work on LDC. They aren’t getting paid for this. If you are a happy LDC user or just like the idea of the project, you can support their work by sponsoring Martin Kinkelin on GitHub.
GDC 11.1 still uses the old C++ version of the D frontend, which feature-wise is mostly (see below) at D 2.076.1. There were significant issues in upstream DMD that prevented Iain from making the switch to the D version of the frontend in time to make the release window. He is currently aiming to make the switch in time for GDC 12. As a consolation, this release has support for three BSDs, Mac OS X, and MinGW!
Despite the older frontend, Iain has backported several fixes and optimizations, and even a few features, so it isn’t your grandfather’s D 2.076.1 that GDC supports. For example, the new bottom type that recently made its way through the D Improvement Proposal review process has found its way into this GDC release. See the forum announcement for details of all the new D goodness in GDC 11.1 and Please consider sponsoring his work on GitHub.
One-off donations
If you aren’t up for sponsoring Martin or Iain but would still like to support them financially, you can make one-time donations through the D Language Foundation. You can send money to the D General Fund, the D Open Collective, or to our PayPal account. Whichever method you choose, please be sure to leave a note that the donation is intended for LDC, GDC, or any D project you would like to support. We’ll make sure the appropriate person receives the money.
Other options for supporting the D programming language: visit the D Language Foundation donation page and donate to one of our funds, head to the DLang Swag Emporium and purchase any items that catch your eye (the D Rocket stuff rocks, and DConf Online 2021 swag will be available shortly), or consider using smile.amazon.com and selecting the D Language Foundation as your charity the next time you shop at Amazon.com (we are only available through the .com domain; browser extensions like SmartAmazonSmile for Firefox and AmazonSmileRedirect for Chrome make it easy to do).
Thanks to everyone who has, will, or continues to support the D programming language, either through donations of time or money. We’ve gotten where we are through community effort, and community effort will keep pushing us forward. D rocks!
This website uses cookies so that we can provide you with the best user experience possible. Cookie information is stored in your browser and performs functions such as recognising you when you return to our website and helping our team to understand which sections of the website you find most interesting and useful.
Strictly Necessary Cookies
Strictly Necessary Cookie should be enabled at all times so that we can save your preferences for cookie settings.
If you disable this cookie, we will not be able to save your preferences. This means that every time you visit this website you will need to enable or disable cookies again.