Introduction
It seems each time you turn around there is a new programming language aimed at solving some specific problem set. Increased proliferation of programming languages and data are deeply connected in a fundamental way, and increasing demand for “data science” computing is a related phenomenon. In the field of scientific computing, Chapel, D, and Julia are highly relevant programming languages. They arise from different needs and are aimed at different problem sets: Chapel focuses on data parallelism on single multi-core machines and large clusters; D was initially developed as a more productive and safer alternative to C++; Julia was developed for technical and scientific computing and aimed at getting the best of both worlds—the high performance and safety of static programming languages and the flexibility of dynamic programming languages. However, they all emphasize performance as a feature. In this article, we look at how their performance varies over kernel matrix calculations and present approaches to performance optimization and other usability features of the languages.
Kernel matrix calculations form the basis of kernel methods in machine learning applications. They scale rather poorly—O(m n^2), where n is the number of items and m is the number of elements in each item. In our exercsie, m will be constant and we will be looking at execution time in each implementation as n increases. Here m = 784 and n = 1k, 5k, 10k, 20k, 30k, each calculation is run three times and an average is taken. We disallow any use of BLAS and only allow use of packages or modules from the standard library of each language, though in the case of D the benchmark is compared with calculations using Mir, a multidimensional array package, to make sure that my matrix implementation reflects the true performance of D. The details for the calculation of the kernel matrix and kernel functions are given here.
While preparing the code for this article, the Chapel, D, and Julia communities were very helpful and patient with all inquiries, so they are acknowledged here.
In terms of bias, going in I was much more familiar with D and Julia than I was with Chapel. However, getting the best performance from each language required a lot of interaction with each programming community, and I have done my best to be aware of my biases and correct for them where necessary.
Language Benchmarks for Kernel Matrix Calculation
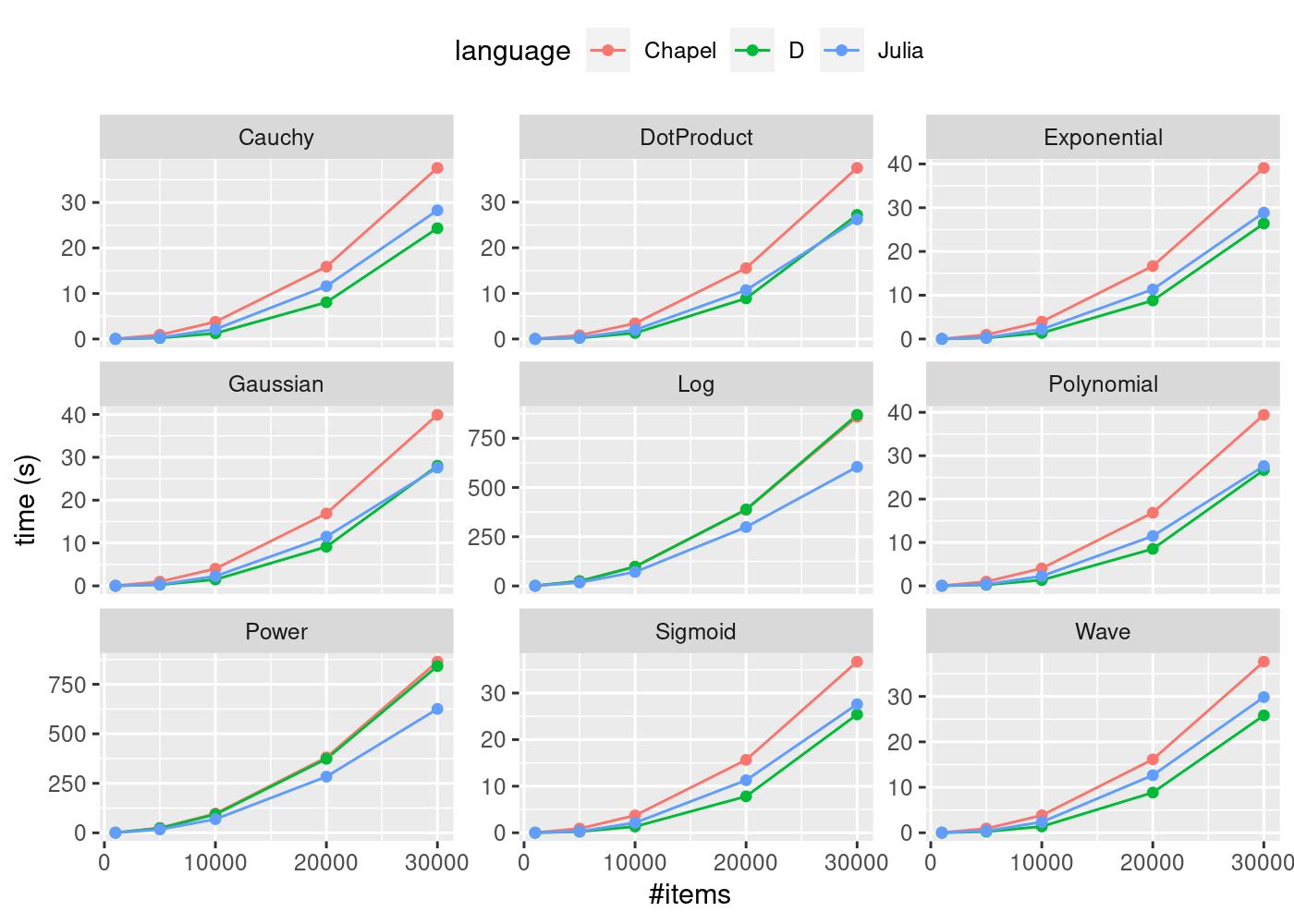
The above chart (generated using R’s ggplot2 using a script) shows the performance benchmark time taken against the number of items n for Chapel, D, and Julia, for nine kernels. D performs best in five of the nine kernels, Julia performs best in two of the nine kernels, and in two of the kernels (Dot and Gaussian) the picture is mixed. Chapel was the slowest for all of the kernel functions examined.
It is worth noting that the mathematics functions used in D were pulled from C’s math API made available in D through its core.stdc.math module because the mathematical functions in D’s standard library std.math can be quite slow. The math functions used are given here. By way of comparison, consider the mathdemo.d script comparing the imported C log function D’s log function from std.math:
$ ldc2 -O --boundscheck=off --ffast-math --mcpu=native --boundscheck=off mathdemo.d && ./mathdemo Time taken for c log: 0.324789 seconds. Time taken for d log: 2.30737 seconds.
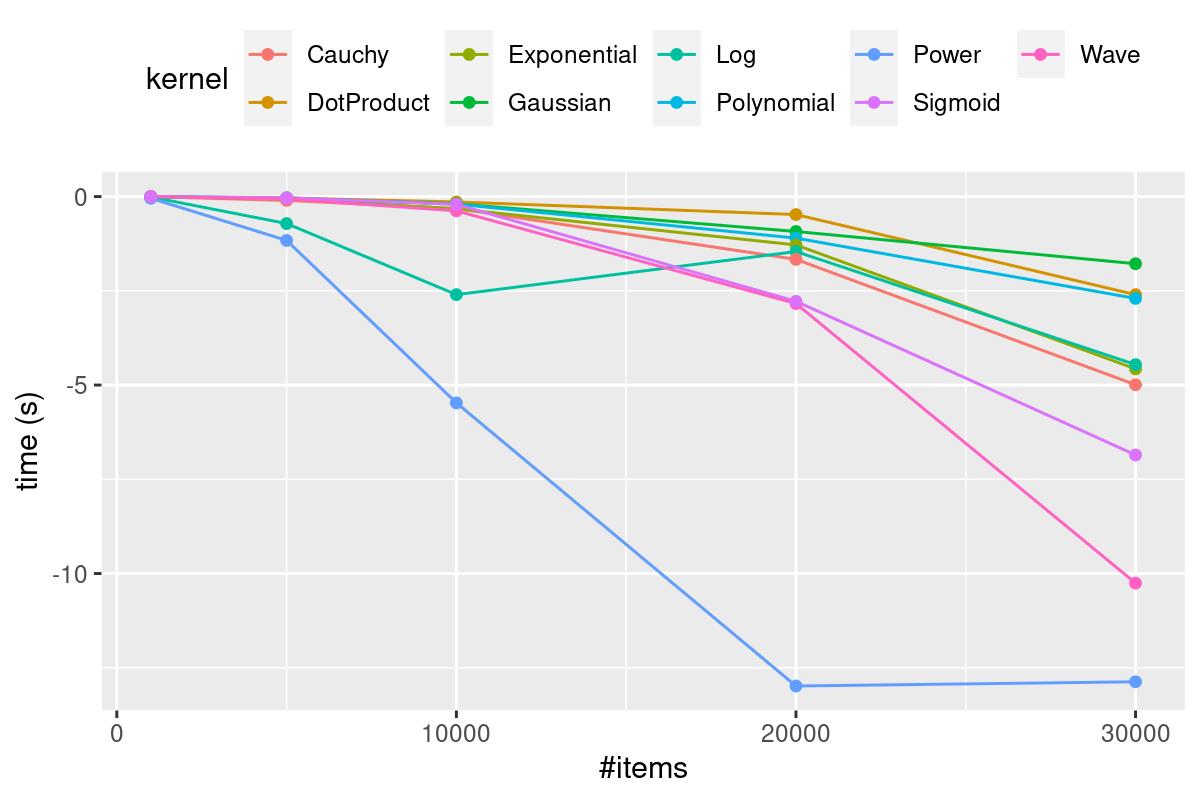
The Matrix object used in the D benchmark was implemented specifically because the use of modules outside standard language libraries was disallowed. To make sure that this implementation is competitive, i.e., it does not unfairly represent D’s performance, it is compared to Mir’s ndslice library written in D. The chart below shows matrix implementation times minus ndslice times; negative means that ndslice is slower, indicating that the implementation used here does not negatively represent D’s performance.
Environment
The code was run on a computer with an Ubuntu 20.04 OS, 32 GB memory, and an Intel® Core™ i9–8950HK CPU @ 2.90GHz with 6 cores and 12 threads.
$ julia --version julia version 1.4.1
$ dmd --version DMD64 D Compiler v2.090.1
ldc2 --version LDC - the LLVM D compiler (1.18.0): based on DMD v2.088.1 and LLVM 9.0.0
$ chpl --version chpl version 1.22.0
Compilation
Chapel:
chpl script.chpl kernelmatrix.chpl --fast && ./script
D:
ldc2 script.d kernelmatrix.d arrays.d -O5 --boundscheck=off --ffast-math -mcpu=native && ./script
Julia (no compilation required but can be run from the command line):
julia script.jl
Implementations
Efforts were made to avoid non-standard libraries while implementing these kernel functions. The reasons for this are:
- To make it easy for the reader after installing the language to copy and run the code. Having to install external libraries can be a bit of a “faff”.
- Packages outside standard libraries can go extinct, so avoiding external libraries keeps the article and code relevant.
- It’s completely transparent and shows how each language works.
Chapel
Chapel uses a forall loop to parallelize over threads. Also, C pointers to each item are used rather than the default array notation, and guided iteration over indices is used:
proc calculateKernelMatrix(K, data: [?D] ?T)
{
var n = D.dim(0).last;
var p = D.dim(1).last;
var E: domain(2) = {D.dim(0), D.dim(0)};
var mat: [E] T;
var rowPointers: [1..n] c_ptr(T) =
forall i in 1..n do c_ptrTo(data[i, 1]);
forall j in guided(1..n by -1) {
for i in j..n {
mat[i, j] = K.kernel(rowPointers[i], rowPointers[j], p);
mat[j, i] = mat[i, j];
}
}
return mat;
}
Chapel code was the most difficult to optimize for performance and required the highest number of code changes.
D
D uses a taskPool of threads from its std.parallel package to parallelize code. The D code underwent the fewest number of changes for performance optimization—a lot of the performance benefits came from the specific compiler used and the flags selected (discussed later). My implementation of a Matrix allows columns to be selected by reference via refColumnSelect.
auto calculateKernelMatrix(alias K, T)(K!(T) kernel, Matrix!(T) data)
{
long n = data.ncol;
auto mat = Matrix!(T)(n, n);
foreach(j; taskPool.parallel(iota(n)))
{
auto arrj = data.refColumnSelect(j).array;
foreach(long i; j..n)
{
mat[i, j] = kernel(data.refColumnSelect(i).array, arrj);
mat[j, i] = mat[i, j];
}
}
return mat;
}
Julia
The Julia code uses the @threads macro for parallelising the code and @views macro for referencing arrays. One confusing thing about Julia’s arrays is their reference status. Sometimes, as in this case, arrays will behave like value objects and they have to be referenced by using the @views macro, otherwise they generate copies. At other times they behave like reference objects, for example, when passing them into a function. It can be a little tricky dealing with this because you don’t always know what set of operations will generate a copy, but where this occurs @views provides a good solution.
The Symmetric type saves the small bit of extra work needed for allocating to both sides of the matrix.
function calculateKernelMatrix(Kernel::K, data::Array{T}) where {K <: AbstractKernel,T <: AbstractFloat}
n = size(data)[2]
mat = zeros(T, n, n)
@threads for j in 1:n
@views for i in j:n
mat[i,j] = kernel(Kernel, data[:, i], data[:, j])
end
end
return Symmetric(mat, :L)
end
The @bounds and @simd macros in the kernel functions were used to turn bounds checking off and apply SIMD optimization to the calculations:
struct DotProduct <: AbstractKernel end
@inline function kernel(K::DotProduct, x::AbstractArray{T, N}, y::AbstractArray{T, N}) where {T,N}
ret = zero(T)
m = length(x)
@inbounds @simd for k in 1:m
ret += x[k] * y[k]
end
return ret
end
These optimizations are quite visible but very easy to apply.
Memory Usage
The total time for each benchmark and the total memory used was captured using the /usr/bin/time -v command. The output for each of the languages is given below.
Chapel took the longest total time but consumed the least amount of memory (nearly 6GB RAM peak memory):
Command being timed: "./script" User time (seconds): 113190.32 System time (seconds): 6.57 Percent of CPU this job got: 1196% Elapsed (wall clock) time (h:mm:ss or m:ss): 2:37:39 Average shared text size (kbytes): 0 Average unshared data size (kbytes): 0 Average stack size (kbytes): 0 Average total size (kbytes): 0 Maximum resident set size (kbytes): 5761116 Average resident set size (kbytes): 0 Major (requiring I/O) page faults: 0 Minor (reclaiming a frame) page faults: 1439306 Voluntary context switches: 653 Involuntary context switches: 1374820 Swaps: 0 File system inputs: 0 File system outputs: 8 Socket messages sent: 0 Socket messages received: 0 Signals delivered: 0 Page size (bytes): 4096 Exit status: 0
D consumed the highest amount of memory (around 20GB RAM peak memory) but took less total time than Chapel to execute:
Command being timed: "./script" User time (seconds): 106065.71 System time (seconds): 58.56 Percent of CPU this job got: 1191% Elapsed (wall clock) time (h:mm:ss or m:ss): 2:28:29 Average shared text size (kbytes): 0 Average unshared data size (kbytes): 0 Average stack size (kbytes): 0 Average total size (kbytes): 0 Maximum resident set size (kbytes): 20578840 Average resident set size (kbytes): 0 Major (requiring I/O) page faults: 0 Minor (reclaiming a frame) page faults: 18249033 Voluntary context switches: 3833 Involuntary context switches: 1782832 Swaps: 0 File system inputs: 0 File system outputs: 8 Socket messages sent: 0 Socket messages received: 0 Signals delivered: 0 Page size (bytes): 4096 Exit status: 0
Julia consumed a moderate amount of memory (around 7.5 GB peak memory) but ran the quickest—probably because its random number generator is the fastest:
Command being timed: "julia script.jl" User time (seconds): 49794.85 System time (seconds): 30.58 Percent of CPU this job got: 726% Elapsed (wall clock) time (h:mm:ss or m:ss): 1:54:18 Average shared text size (kbytes): 0 Average unshared data size (kbytes): 0 Average stack size (kbytes): 0 Average total size (kbytes): 0 Maximum resident set size (kbytes): 7496184 Average resident set size (kbytes): 0 Major (requiring I/O) page faults: 794 Minor (reclaiming a frame) page faults: 38019472 Voluntary context switches: 2629 Involuntary context switches: 523063 Swaps: 0 File system inputs: 368360 File system outputs: 8 Socket messages sent: 0 Socket messages received: 0 Signals delivered: 0 Page size (bytes): 4096 Exit status: 0
Performance optimization
The process of performance optimization in all three languages was very different, and all three communities were very helpful in the process. But there were some common themes.
- Static dispatching of kernel functions instead of using polymorphism. This means that when passing the kernel function, use parametric (static compile time) polymorphism rather than runtime (dynamic) polymorphism where dispatch with virtual functions carries a performance penalty.
- Using views/references rather than copying data over multiple threads makes a big difference.
- Parallelising the calculations makes a huge difference.
- Knowing if your array is row/column major and using that in your calculation makes a huge difference.
- Bounds checks and compiler optimizations make a tremendous difference, especially in Chapel and D.
- Enabling SIMD in D and Julia made a contribution to the performance. In D this was done using the
-mcpu=nativeflag, and in Julia this was done using the@simdmacro.
In terms of language-specific issues, getting to performant code in Chapel was the most challenging, and the Chapel code changed the most from easy-to-read array operations to using pointers and guided iterations. But on the compiler side it was relatively easy to add --fast and get a large performance boost.
The D code changed very little, and most of the performance was gained by the choice of compiler and its optimization flags. D’s LDC compiler is rich in terms of options for performance optimization. It has 8 -O optimization levels, but some are repetitions of others. For instance, -O, -O3, and -O5 are identical, and there are myriad other flags that affect performance in various ways. In this case the flags used were -O5 --boundscheck=off –ffast-math, representing aggressive compiler optimizations, bounds checking, and LLVM’s fast-math, and -mcpu=native to enable CPU vectorization instructions.
In Julia the macro changes discussed previously markedly improved the performance, but they were not too intrusive. I tried changing the optimization -O level, but this did not improve performance.
Quality of life
This section examines the relative pros and cons around the convenience and ease of use of each language. People underestimate the effort it takes to use a language day-to-day; the support and infrastructure required is significant, so it is worth comparing various facets of each language. Readers seeking to avoid the TLDR should scroll to the end of this section for the table comparing the language features discussed here. Every effort has been made to be as objective as possible, but comparing programming languages is difficult, bias prone, and contentious, so read this section with that in mind. Some elements looked at, such as arrays, are from the “data science”/technical/scientific computing point of view, and others are more general.
Interactivity
Programmers want a fast code/compile/result loop during development to quickly observe results and outputs in order to make progress or necessary changes. Julia’s interpreter is hands down the best for this and offers a smooth and feature-rich development experience, and D comes a close second. This code/compile/result loop in compilers can be slow even when compiling small code volumes. D has three compilers, the standard DMD compiler, the LLVM-based LDC compiler, and the GCC-based GDC. In this development process, the DMD and LDC compilers were used. DMD has very fast compilation times which is great for development. The LDC compiler is great at creating fast code. Chapel’s compiler is very slow in comparison. To give an example, running Linux’s time command on DMD vs Chapel’s compiler for the kernel matrix code with no optimizations gives us for D:
real 0m0.545s user 0m0.447s sys 0m0.101s
Compared with Chapel:
real 0m5.980s user 0m5.787s sys 0m0.206s
That’s a large actual and psychological difference, it can make programmers reluctant to check their work and delay the development loop if they have to wait for outputs, especially when source code increases in volume and compilation times become significant.
It is worth mentioning, however, that when developing packages in Julia, compilation times can be very long, and users have noticed that when they load some packages ,compilation times can stretch. So the experience of the development loop in Julia could vary, but in this specific case the process was seamless.
Documentation and examples
One way of comparing documentation in the different languages is to compare them all with Python’s official documentation, which is the gold standard for programming languages. It combines examples with formal definitions and tutorials in a seamless and user-friendly way. Since many programmers are familiar with the Python documentation, this approach gives an idea of how they compare.
Julia’s documentation is the closest to Python’s documentation quality and gives the user a very smooth, detailed, and relatively painless transition into the language. It also has a rich ecosystem of blogs, and topics on many aspects of the language are easy to come by. D’s official documentation is not as good and can be challenging and frustrating, however there is a very good free book “Programming in D” which is a great introduction to the language, but no single book can cover a programming language and there are not many sources for advanced topics. Chapel’s documentation is quite good for getting things done, though examples vary in presence and quality. Often, the programmer needs a lot of knowledge to look in the right place. A good topic for comparison is file I/O libraries in Chapel, D, and Julia. Chapel’s I/O library has too few examples but is relatively clear and straightforward; D’s I/O is kind of spread across a few modules, and documentation is more difficult to follow; Julia’s I/O documentation has lots of examples and is clear and easy to follow.
Perhaps one factor affecting Chapel’s adoption is lack of example—since its arrays have a non-standard interface, the user has to work hard to become familiar with them. Whereas even though D’s documentation may not be as good in places, the language has many similarities to C and C++, so it gets away with more sparse documentation.
Multi-dimensional Array support
“Arrays” here does not refer to native C and C++ style arrays available in D, but mathematical arrays. Julia and Chapel ship with array support and D does not, but it has the Mir library which has multidimensional arrays (ndslice). In the implementation of kernel matrix, I wrote my own matrix object in D, which is not difficult if you understand the principle, but it’s not something a user wants to do. However, D has a linear algebra library called Lubeck which has impressive performance characteristics and interfaces with all the usual BLAS implementations. Julia’s arrays are by far the easiest and most familiar. Chapel’s arrays are more difficult to get started with than Julia’s but are designed to be run on single-core, multi-core, and computer clusters using the same or very similar code, which is a good unique selling point.
Language power
Since Julia is a dynamic programming language, some might say, “well Julia is a dynamic language which is far more permissive than static programming languages, therefore the debate is over”, but it’s more complicated than that. There is power in static type systems. Julia has a type system similar in nature to type systems from static languages, so you can write code as if you were using a static language, but you can do things reserved only for dynamic languages. It has a highly developed generic and meta-programming syntax and powerful macros. It also has a highly flexible object system and multiple dispatch. This mix of features is what makes Julia the most powerful language of the three.
D was intended to be a replacement for C++ and takes very much after C++ (and also borrows from Java), but makes template programming and compile-time evaluation much more user-friendly than in C++. It is a single dispatch language (though multi-methods are available in a package). Instead of macros, D has string and template “mixins” which serve a similar purpose.
Chapel has generic programming support and nascent support for single dispatch OOP, no macro support, and is not yet as mature as D or Julia in these terms.
Concurrency & Parallel Programming
Nowadays, new languages tout support for concurrency and its popular subset, parallelism, but the details vary a lot between languages. Parallelism is more relevant in this example and all three languages deliver. Writing parallel for loops is straightforward in all three languages.
Chapel’s concurrency model has much more emphasis on data parallelism but has tools for task parallelism and ships with support for cluster-based concurrency.
Julia has good support for both concurrency and parallelism.
D has industry strength support for parallelism and concurrency, though its support for threading is much less well documented with examples.
Standard Library
How good is the standard library of all three languages in general? What range of tasks do they allow users to easily tend to? It’s a tough question because library quality and documentation factor in. All three languages have very good standard libraries. D has the most comprehensive standard library, but Julia is a great second, then Chapel, but things are never that simple. For example, a user seeking to write binary I/O may find Julia the easiest to start with; it has the most straightforward, clear interface and documentation, followed by Chapel, and then D. Though in my implementation of an IDX file reader, D’s I/O was the fastest, but then Julia code was easy to write for cases unavailable in the other two languages.
Package Managers & Package Ecosystems
In terms of documentation, usage, and features, D’s Dub package manager is the most comprehensive. D also has a rich package ecosystem in the Dub website, Julia’s package manager runs tightly integrated with GitHub and is a good package system with good documentation. Chapel has a package manager but does not have a highly developed package ecosystem.
C Integration
C interop is easy in all three languages; Chapel has good documentation but is not as well popularised as the others. D’s documentation is better and Julia’s documentation is the most comprehensive. Oddly enough though, none of the languages’ documentation show the commands required to compile your own C code and integrate it with the language, which is an oversight especially when it comes to novices. It is, however, easy to search for and find examples for the compilation process in D and Julia.
Community
All three languages have convenient places where users can ask questions. For Chapel, the easiest place is Gitter, for Julia it’s Discourse (though there is a Julia Gitter), and for D it’s the official website forum. The Julia community is the most active, followed by D, and then Chapel. I’ve found that you’ll get good responses from all three communities, but you’ll probably get quicker answers from the D and Julia communities.
| Chapel | D | Julia | |
|---|---|---|---|
| Compilation/Interactivty | Slow | Fast | Best |
| Documentation & Examples | Detailed | Patchy | Best |
| Multi-dimensional Arrays | Yes | Native Only (library support) |
Yes |
| Language Power | Good | Great | Best |
| Concurrency & Parallelism | Great | Great | Good |
| Standard Library | Good | Great | Great |
| Package Manager & Ecosystem | Nascent | Best | Great |
| C Integration | Great | Great | Great |
| Community | Small | Vibrant | Largest |
Table for quality of life features in Chapel, D & Julia
Summary
If you are a novice programmer writing numerical algorithms and doing calculations based in scientific computing and want a fast language that’s easy to use, Julia is your best bet. If you are an experienced programmer working in the same space, Julia is still a great option. If you specifically want a more conventional, “industrial strength”, statically compiled, high-performance language with all the “bells and whistles”, but want something more productive, safer, and less painful than C++, then D is your best bet. You can write “anything” in D and get great performance from its compilers. If you need to get array calculations happening on clusters, then Chapel is probably the easiest place to go.
In terms of raw performance on this task, D was the winner, clearly performing better in 5 out of the 9 kernels benchmarked. This exercise reveals that Julia’s label as a high-performance language is more than just hype—it has held it’s own against highly competitive languages. It was harder than expected to get competitive performance from Chapel—it took a lot of investigation from the Chapel team to come up with the current solution. However, as the Chapel language matures we could see further improvement.
You wrote: “For Chapel, the easiest place is Gitter, for Julia it’s Discourse (though there is a Julia Gitter), and for D it’s the official website forum.”
You probably meant that there is a Julia Slack, not Gitter. Folks tend to be pretty helpful on the Slack. There’s also a Zulip; that has less traffic, but has the advantage of being permanent.